
Release of SQX 139 Dev 1 and what’s planned for year 2024
We’d like to announce the release of the new SX 139 Dev 1 version – note that this is a development version for testing, not the final 139 version. Most …
Přejít k obsahu | Přejít k hlavnímu menu | Přejít k vyhledávání
The new SQ build 125 introduces multiple data range parts. Until now, you were able to divide your history data to two parts only:
The new build 125 adds two more possible types, making it 4 in total:
The general recommendation in machine learning is to split the history data to 3 same parts: IST, ISV and OOS.

Another possible split could be 60/20/20, or move Out of Sample period to the front.
Another new feature if SQ X B 125 is that you can define multiple In Sample Validation or Out of Sample parts, not just one, and in any order you want.
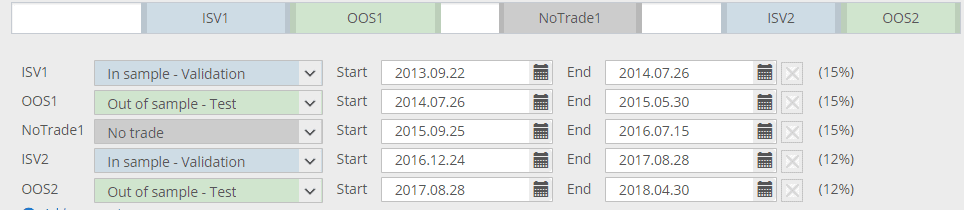
In the picture above the white parts are all In Sample training – these are the data on which strategies are evolved.
Blue (ISV) parts are data on which strategies are verified, and evolution can be restarted when it is stagnating.
Gray (no trade) part is the one that is left out – strategy doesn’t trade here.
Green parts are OOS parts – they are not part of genetic evolution and strategies are evaluated on unknown data.
All metrics are now computed also independently for each of these parts, and you can use them in your conditions.
For example, you can filter out strategies where: Net profit (OOS1) is worse than 80% of Net profit (OOS2).
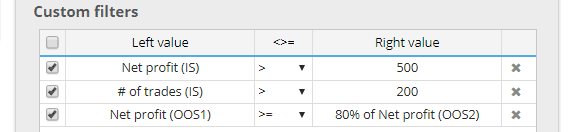
This allows you to use “stricter” filtering where strategy has to perform well on multiple parts of data.
We’d like to announce the release of the new SX 139 Dev 1 version – note that this is a development version for testing, not the final 139 version. Most …

Dive into Algorithmic Trading Without the Coding Headache! Are you intrigued by algorithmic trading but dread the thought of coding? Today marks the beginning of our exciting series that’s about …
 Tomas Vanek
Tomas Vanek5. 3. 2024
In this interview, we catch up with Naoufel, a seasoned trader, to explore his journey through the stormy market of 2023. Naoufel is successful trader with verfied track record who …
 Ellie Souckova
Ellie Souckova12. 12. 2023
Thank you
Here, for Net profit (IS) , IS includes IST and ISV1 and ISV2. Am I right?
Good question. Anybody from the SQ team who want to answer?
Yes, correct
i feel very dumb trying to understand what this means.
if you have a specific questions feel free to ask
Can you explain with more details what’s the difference between ISV and OOS? Maybe is something related to machine learning but I don’t get it
That is a data part in SQ X that is used to determine if strategy performance in IST (training part) holds also in ISV part. In SQ X it can be used to restart genetic evolution when fitness stagnates in this part. So it is kind of semi-OOS used to verify performance before it is verified on OOS