En la entrada del blog de hoy, intentaré resumir algunas ideas importantes del libro Evidence Based Technical Analysis de David Aronson. El libro se publicó en 2006 y se hizo popular con bastante rapidez.
El Análisis Técnico Basado en Pruebas aborda temáticamente la cuestión del análisis estadístico en el contexto del desarrollo de estrategias y la cuestión de la minería de datos que preocupa a los usuarios. StrategyQuant x es de facto una sofisticada herramienta de minería de datos que debe desplegarse y configurarse de forma que se reduzca el riesgo de que el rendimiento de la estrategia sea en realidad producto del azar.
La primera parte aborda cuestiones filosóficas del conocimiento científico. Aborda el análisis técnico y el análisis como táctica desde la perspectiva de la filosofía, la metodología y la lógica, y en general se centra más en las cuestiones teóricas y filosóficas y sus implicaciones para la práctica.
La segunda parte aborda el uso y los argumentos para utilizar métodos estadísticos rigurosos, en particular estadísticas de interferencia, en el análisis del rendimiento de una estrategia algorítmica. La tercera parte aborda lo que más nos puede preocupar como usuarios de SQX: los sesgos de la minería de datos asociados a los métodos de comparación múltiple. La cuarta parte aborda el uso de diversos métodos en la minería de datos, incluido el uso de algoritmos en la búsqueda de estrategias, el uso de métodos de confirmación en la minería de datos, etc.
Esta entrada del blog pretende extraer los conceptos básicos con los que trabaja David Aronson y aplicarlos al tema del desarrollo de StrategyQuant X. Me he centrado en las partes que más preocupan a los usuarios de SQX, teniendo en cuenta los errores más comunes que cometen los novatos a la hora de configurar el programa.
Cito en primer lugar la breve BIO de David Aronson:
[1]" David Aronson, autor de "Análisis técnico basado en pruebas" (John Wiley & Son's 2006) es profesor adjunto de finanzas en la Zicklin School of Business, donde imparte un curso de postgrado sobre análisis técnico y minería de datos desde 2002.
En 1977, Aronson abandonó Merrill Lynch para iniciar un estudio independiente del incipiente campo de las estrategias de futuros gestionados y en 1980 creó AdvoCom Corporation, una de las primeras en adoptar los métodos modernos de la teoría de carteras y las bases de datos informatizadas de rendimiento para la creación de carteras y fondos de futuros multiasesor. Una cartera representativa que comenzó en 1984 ha obtenido un rendimiento anual compuesto del 23,7%. En 1990, AdvoCom asesoró a Tudor Investment Corporation en su fondo público multiasesor.
A finales de los setenta, mientras investigaba estrategias informatizadas para futuros gestionados, Aronson se dio cuenta del potencial de aplicar la inteligencia artificial al descubrimiento de patrones predictivos en los datos de los mercados financieros. Esta práctica, que ahora está ganando aceptación en Wall Street, se conoce como minería de datos. En 1982, Aronson fundó Raden Research Group, uno de los primeros en aplicar la minería de datos y los modelos predictivos no lineales al desarrollo de métodos de negociación sistemática. La innovación de Aronson consistió en aplicar la minería de datos para mejorar las estrategias de negociación tradicionales informatizadas. Este enfoque se describió por primera vez en el artículo de Aronson, "Pattern Recognition Signal Filters", Market Technican's Journal - Primavera de 1991. Raden Research Group Inc. llevó a cabo investigaciones sobre modelos predictivos y desarrollo de filtros por encargo de varias empresas de negociación, entre ellas Tudor Investment Corporation, Manufacturers Hanover Bank, Transworld Oil, Quantlabs y varios grandes operadores individuales."
El libro comienza con una definición de los conceptos básicos del análisis técnico e intenta definir todo el tema desde el punto de vista de la lógica. Trata cuestiones filosóficas, metodológicas, estadísticas y psicológicas del análisis de los mercados financieros y hace hincapié en la importancia del pensamiento, el juicio y el razonamiento científicos.
Aronson trabaja con dos definiciones de análisis técnico
- Análisis técnico subjetivo (AT)
- Análisis técnico objetivo (AT)
El AT subjetivo, según Aronson, no utiliza métodos y procedimientos científicos repetibles. Se basa en las interpretaciones personales de los analistas y es difícil de probar desde una perspectiva histórica mediante backtesting. En cambio, el la AT objetiva se basa en el uso de métodos de backtesting y en el uso de análisis estadísticos objetivos de los resultados del backtestingsegún Aronson.
El uso de métodos científicos en el análisis técnico/cuantitativo es el tema básico de todo el libro.
[2] "El AT objetivo también puede generar creencias erróneas, pero éstas se producen de forma diferente. Se deben a inferencias erróneas a partir de pruebas objetivas. El mero hecho de que un método objetivo haya sido rentable en una prueba retrospectiva no es motivo suficiente para concluir que tiene mérito. El rendimiento pasado puede engañarnos. El éxito histórico es una condición necesaria pero no suficiente para concluir que un método tiene poder predictivo y, por tanto, es probable que sea rentable en el futuro. Un rendimiento pasado favorable puede producirse por suerte o debido a un sesgo al alza producido por una forma de backtesting denominada minería de datos. Determinar cuándo los beneficios del backtesting son atribuibles a un buen método y no a la suerte es una cuestión que sólo puede responderse mediante una inferencia estadística rigurosa."
Aronson critica los métodos subjetivos de AT, pero también subraya que pueden cometerse errores incluso cuando se utiliza la AT objetiva.
En esta parte, me interesó mucho la parte sobre las diversas formas de errores que son comunes o se producen al resolver problemas analíticos. Entre los métodos de análisis están los llamados sesgos que se producen al entender las cosas
- Sesgo de exceso de confianza
- Sesgo de optimismo
- Sesgo de confirmación
- Sesgo de selección
- Correlaciones ilusorias
- Sesgo de optimismo
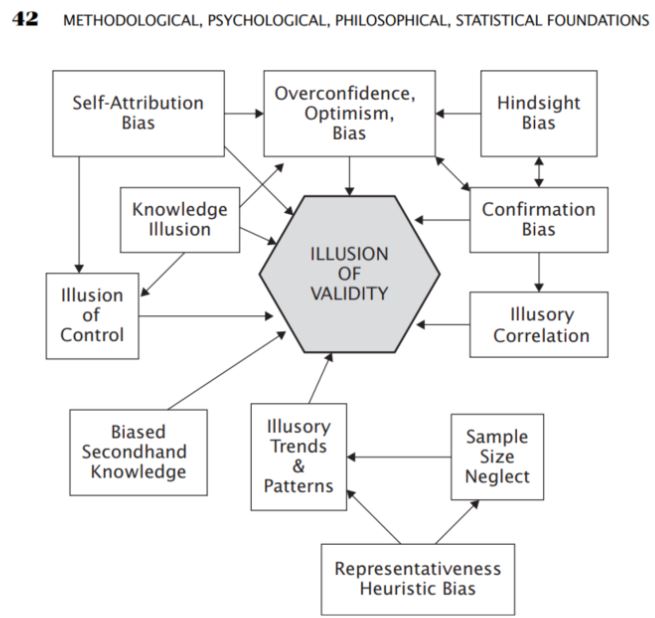
Fuente: Aronson, D. R. (2021). En Análisis técnico basado en pruebas: Aplicación del método científico y la inferencia estadística a las señales de negociación (pp. 42-42). ensayo, John Wiley & Sons.
Es el análisis subjetivo del AT el que a menudo puede basarse en los sesgos descritos por Aronson, pero éste señala que incluso con el AT objetivo - estadístico los sesgos se producen a menudo de forma inconsciente. Por ello, propone el uso de la llamada AT objetiva en forma de aplicación de métodos científicos en el análisis.
Aronson resume los pasos de la formulación de hipótesis en el análisis de interferencias - método deductivo
- Observación
- Hipótesis
- Predicción
- Verificación
- Conclusión
En los capítulos siguientes, Aronson explica la importancia de un análisis estadístico riguroso para evaluar las estrategias.
[3]"La estadística inferencial ayuda a comprender bien los datos de la población analizando las muestras obtenidas de ella. Ayuda a hacer generalizaciones sobre la población utilizando diversas pruebas y herramientas analíticas. Para seleccionar muestras aleatorias que representen con exactitud a la población se utilizan muchas técnicas de muestreo. Algunos de los métodos importantes son el muestreo aleatorio simple, el muestreo estratificado, el muestreo por conglomerados y las técnicas de muestreo sistemático."
Aronson lo define en el contexto del uso del Análisis Técnico:
[4]"Identificar qué métodos de AT tienen un verdadero poder predictivo es muy incierto. Incluso las reglas más potentes muestran un rendimiento muy variable de un conjunto de datos a otro. Por lo tanto, el análisis estadístico es la única forma práctica de distinguir los métodos que son útiles de los que no lo son. Lo reconozcan o no sus practicantes, la esencia de la TEA es la inferencia estadística. Trata de descubrir generalizaciones a partir de datos históricos en forma de patrones, reglas, etc. para luego extrapolarlas al futuro. La extrapolación es inherentemente incierta. La incertidumbre es incómoda".
En el contexto del desarrollo de estrategias en StrategyQuant, X puede verse como una muestra de la población.
- Lista de operaciones y sus métricas
- Lista de estrategias en la base de datos y sus métricas estratégicas
No quiero marginar los temas de las estadísticas de interferencia, las pruebas de hipótesis y las estadísticas descriptivas, pero su alcance e implicaciones van mucho más allá del ámbito de este artículo, por lo que
Le recomiendo que consulte estos recursos:
Minería de datos
[5]La minería de datos es la extracción de conocimientos, en forma de patrones, reglas, modelos, funciones, etc., a partir de grandes bases de datos.
Para nosotros, como usuarios de StrategyQuant X, es probable que utilicemos algún tipo de minería de datos en nuestra búsqueda de estrategias rentables
Con StrategyQuant X, normalmente utilizamos la minería de datos cuando buscamos
- Búsqueda de estrategias ( Constructor )
- Optimización de la estrategia ( Optimización )
Aronson menciona las diferencias entre el desarrollo clásico de estrategias y la minería de datos:
- Consideramos que el método clásico es aquel en el que un desarrollador crea un estrategia desde cero sin utilizar métodos de minería de datos. En el contexto de StrategyQuant X, podríamos pensar en la creación manual de estrategias en Algowizard, donde podemos crear estrategias según nuestra lógica.
- Al utilizar la minería de datos, probamos un gran número de reglas para encontrar la estrategia con el mayor rendimiento observado y la mayor probabilidad de rendimiento futuro..
Aronson defiende el uso de la minería de datos del siguiente modo:
-
[6]En primer lugar, funciona. Los experimentos que se presentan más adelante en este capítulo demostrarán que, en condiciones bastante generales, cuanto mayor sea el número de reglas que se vuelven a probar, mayor será la probabilidad de encontrar una regla buena.
-
En segundo lugar, las tendencias tecnológicas favorecen la minería de datos. La rentabilidad de los ordenadores personales, la disponibilidad de potentes programas informáticos de back-testing y minería de datos, y la disponibilidad de bases de datos históricas hacen ahora que la minería de datos sea práctica para los particulares. Hace tan sólo una década, los costes limitaban la extracción de datos a los inversores institucionales.
-
En tercer lugar, en su fase actual de evolución, el AT carece de la base teórica que permitiría un enfoque científico más tradicional de la adquisición de conocimientos
Sesgo de la minería de datos
Aronson sostiene que los sesgos en la extracción de datos podrían ser una de las principales razones del fracaso de las estrategias en operaciones fuera de muestra o reales.
[7]"Sesgo de minería de datos: diferencia esperada entre el rendimiento observado de la mejor regla y su rendimiento esperado. La diferencia esperada se refiere a una diferencia media a largo plazo que se obtendría mediante numerosos experimentos que miden la diferencia entre el rendimiento observado de la mejor regla y el rendimiento esperado de la mejor regla."
Considera los dos componentes principales del rendimiento observado (rendimiento de la estrategia) de la siguiente manera.
- Previsibilidad de la estrategia
- Azar - Suerte
[8]"Ahora llegamos a un principio importante. Cuanto mayor sea la contribución de la aleatoriedad (suerte) en relación con el mérito en el rendimiento observado (resultados de las pruebas retrospectivas), mayor será la magnitud del sesgo de la minería de datos. La razón es la siguiente: Cuanto mayor sea el papel de la suerte en relación con el mérito, mayor será la probabilidad de que una de las muchas reglas candidatas ( estrategias ) experimente un rendimiento extraordinariamente afortunado. Este es el candidato que seleccionará el minero de datos. Sin embargo, en situaciones en las que el rendimiento observado se debe estricta o principalmente al verdadero mérito de un candidato, el sesgo de la minería de datos será inexistente o muy pequeño. En estos casos, el rendimiento pasado de un candidato será un predictor fiable del rendimiento futuro y el minero de datos raramente llenará la tolva con oro de los tontos. Dado que los mercados financieros son extremadamente difíciles de predecir, la mayor parte del rendimiento observado de una regla se deberá al azar y no a su poder predictivo. "
En el contexto de StrategyQuant X, podemos decir que el elemento de azar está asociado a la actitud más benévola de StrategyQuant X. Ii elegimos demasiadas combinaciones al buscar estrategias, StrategyQuant X puede encontrar una que tenga un backtest positivo pero que no funcione en la realidad de la estrategia. A continuación, al final de la entrada del blog, los factores que influyen en esta aleatoriedad se resumen con consejos en la configuración de StrategyQuant X.
También se presta mucha atención al Procedimiento de Comparación Múltiple (PCM ). Wikipedia define los procedimientos de comparación múltiple como :
[9]"Las comparaciones múltiples surgen cuando un análisis estadístico implica múltiples pruebas estadísticas simultáneas, cada una de las cuales tiene el potencial de producir un "descubrimiento". Un nivel de confianza establecido generalmente se aplica sólo a cada prueba considerada individualmente, pero a menudo es deseable tener un nivel de confianza para toda la familia de pruebas simultáneas."
En el contexto de StrategyQuant X, podemos aplicar el problema de las comparaciones múltiples siempre que busquemos un gran número de indicadores/condiciones/configuraciones de una estrategia concreta en un amplio espectro. Utilizando los métodos de comparaciones múltiples, podemos determinar fácilmente que la solución encontrada, en nuestro caso la estrategia y su rendimiento fuera de muestra es fruto del azar y de un gran número de combinaciones probadas. Cuantas más reglas y más variabilidad se utilicen en la configuración SQX, mayor será la probabilidad de que el rendimiento de la estrategia en OS sea producto del azar y, por lo tanto, mayor será la probabilidad de que la estrategia falle en el trading real.
Aronson demuestra las conclusiones presentadas en la siguiente sección ejecutando experimentalmente las reglas de negociación basadas en datos para el índice S&P 500 durante el periodo comprendido entre 1328 y 2003. El procedimiento exacto se puede encontrar en la página 292. Un experimento similar se puede repetir fácilmente en StrategyQuant X para cualquier mercado.
5 factores que influyen en el grado de sesgo de la minería de datos
-
Número de normas comprobadas:
[10]"Se refiere al número total de reglas sometidas a backtesting durante el proceso de minería de datos para descubrir la regla de mayor rendimiento. Cuanto mayor sea el número de reglas probadas, mayor será el sesgo de la minería de datos".
Implicaciones Número de reglas comprobadas al desarrollar estrategias en StrategyQuant X
El número de Reglas usadas en la búsqueda de estrategias puede ser influenciado en StrategyQuant X en los siguientes ajustes en Constructor/ Qué construir:
- Rango de parámetros ( periodos)
- Periodo de retrospectiva
- Ajustes de Stop Loss y objetivos de beneficios
- Establezca el número máximo de reglas en caso de entrada y salida
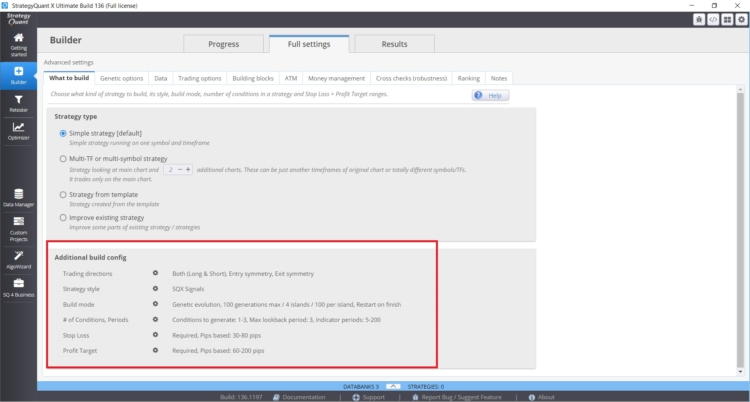
En este caso, cuanto mayores sean los valores y rangos especificados, mayor será el riesgo de sesgo en la extracción de datos.. Una buena práctica es utilizar un máximo de dos reglas de entrada, para el período de retroceso me quedaría con un valor máximo de 3. A menudo veo de los clientes estrategias con 6 condiciones y períodos de retroceso de 25. Hay un riesgo real de sesgo de minería de datos con estas combinaciones. Existe un riesgo real de sesgo de minería de datos con estas combinaciones.
Si desea establecer periodos de retrospección específicos para bloques concretos en los que tenga sentido (cierre diario, etc.), puede establecerlos directamente para una regla concreta, como puede ver en la figura siguiente:
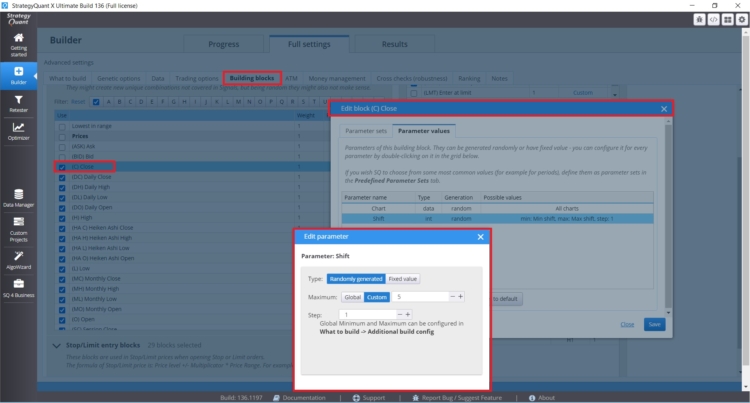
También puede controlar directamente los tipos, la cantidad y los ajustes de los bloques de construcción en la pestaña Constructor con Indies/Reglas de entrada.
Número de indicadores, condiciones y bloques de comparación:
- Número de bloques de entrada posibles
- Número de bloques de salida posibles
- En el caso de las órdenes Stop/Limit es importante el número de indicadores stop limit
- Tipos de salidas y entradas y su configuración.
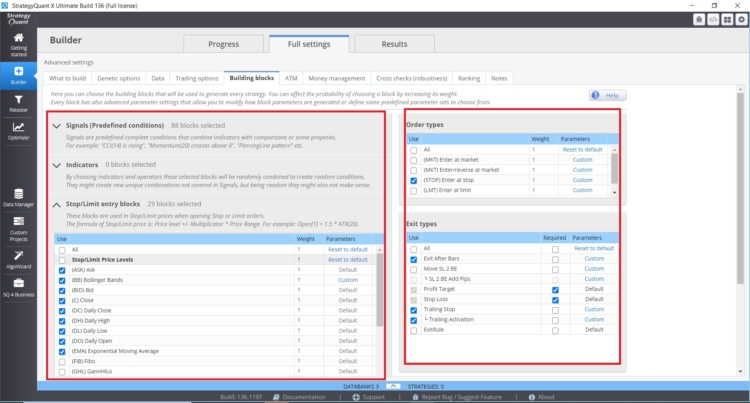
Cuantas más opciones pongamos en el motor genético de StrategyQuant X, mayor puede ser el sesgo de la minería de datos.
-
Número de observaciones utilizadas para calcular la estadística de rendimiento:
[11]Cuanto mayor sea el número de observaciones, menor será el sesgo de extracción de datos.
Implicaciones del número de observaciones en el desarrollo de estrategias en StrategyQuant X:
En general, Cuanto mayor sea la muestra de datos (número de operaciones realizadas fuera de la muestra), mayor será la potencia estadística de los resultados.
Para ello:
- Mayores datos fuera de la muestra = mayor tamaño de la muestra
- Más mercados analizados = mayor tamaño de la muestra
- Más periodos de tiempo probados = mayor tamaño de la muestra
Asimismo, desde el punto de vista de las estadísticas de interferencia, los indicadores de estrategia identificados tienen un mayor valor predictivo cuando la muestra es lo suficientemente grande Del mismo modo, las estadísticas de estrategia identificadas tienen más peso cuando el tamaño de la muestra identificada es mayor. Cabe destacar que no es necesario tener en cuenta los resultados dentro de la muestra si el rendimiento fuera de la muestra de la estrategia es de mayor valor. Sin embargo, esto también se ve afectado por los sesgos de extracción de datos asociados al procedimiento de comparación múltiple. En la práctica, esto puede significar que es muy probable que el rendimiento real sea peor que el rendimiento del backtest fuera de muestra.
Aronson considera que este punto es el más importante de todos los factores. Sostiene que cuanto mayor sea la muestra de datos obtenida, menor será el impacto negativo de los demás factores. Cuando optimice una estrategia existente, preste atención a los rangos de los parámetros y al número de pasos. En general, cuantas más opciones, más posibilidades de azar.
Como establecer el rango de backtest y el periodo fuera de muestra en StrategyQuant X
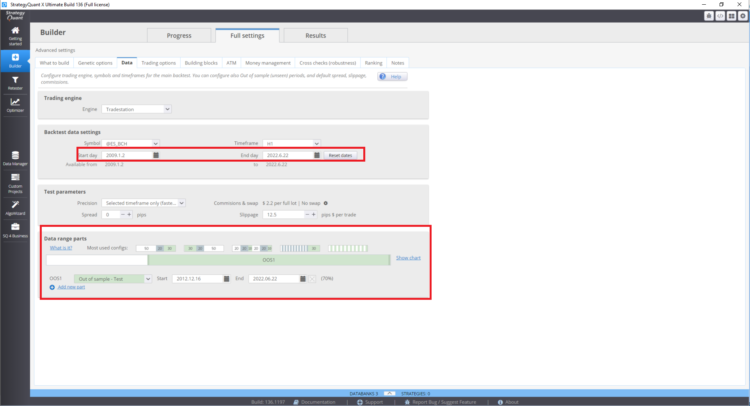
Cómo organizar pruebas multimercado
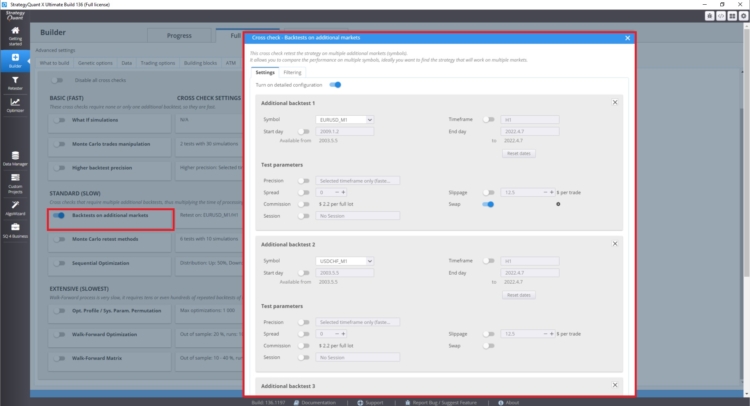
En la sección de comprobación cruzada, en Backtest en mercados adicionales, puede establecer backtests en mercados adicionales.
Dónde establecer la función de fitness y el ranking true en StrategyQuant X
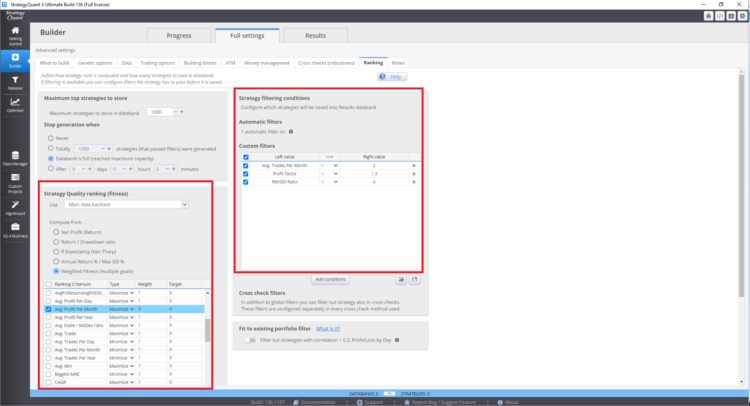
Estos ajustes pueden afectar a las estrategias resultantes en el banco de datos.
-
Correlación entre los rendimientos de las normas
[12]Se refiere al grado en que los historiales de rendimiento de las reglas probadas están correlacionados entre sí. Cuanto menos correlacionados estén, mayor será el sesgo de la minería de datos.
Cuanto mayor sea la correlación entre las reglas probadas, menor será la magnitud del sesgo. Por el contrario, cuanto menor sea la correlación (es decir, cuanto mayor sea el grado de independencia estadística) entre las reglas devueltas, mayor será el sesgo de la extracción de datos. Esto tiene sentido porque una mayor correlación entre las reglas tiene como consecuencia la reducción del número efectivo de reglas sometidas a back-testing.
Este punto es difícil de comprender. Se basa en el conocimiento del primer punto. El número de estrategias correlacionadas en el StrategyQuantX puede verse afectado por el tipo de bloques de construcción utilizados en la construcción de estrategias, pero también por la configuración de la búsqueda genética de estrategias. Por ejemplo, si elige sólo medias móviles como bloques de construcción, es más probable que las estrategias estén más correlacionadas entre sí.
Si el número de bloques de construcción es muy bajo, no se aprovechará el potencial de la minería de datos; por el contrario, si el número de bloques de construcción es muy alto, se corre el riesgo de un gran sesgo de la minería de datos. Estos factores también pueden eliminarse con un número elevado de operaciones o con pruebas multimercado.
Puede gestionar estos ajustes en Constructor/ Opciones genéticas.
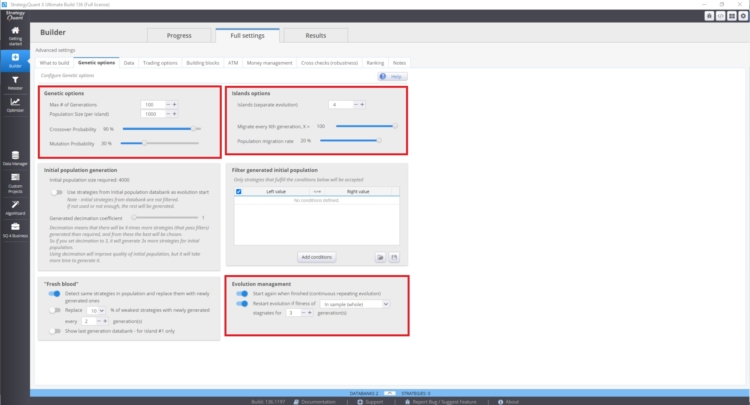
La velocidad de convergencia de la curva de aptitud y la variabilidad de las estrategias dependen de:
- Mayor valor de la probabilidad de cruce
- Valor inferior de la probabilidad de mutación
La evolución de las islas también puede tener un gran impacto. Esto permite la migración de estrategias entre islas. La gestión evolutiva también puede desempeñar un papel importante. Sobre todo si reiniciamos la evolución genética con demasiadas generaciones. Puede acabar con más estrategias correlacionadas en el banco de datos.
Estos ajustes pueden ser contradictorios y su uso depende de cada caso. Este problema no es fácil de entender, porque el estado de tu base de datos depende de muchos factores.
-
Presencia de rendimientos atípicos positivos
[13]Se refiere a la presencia de rendimientos muy grandes en el historial de rendimiento de una regla, por ejemplo, un rendimiento positivo muy grande en un día concreto. Cuando están presentes, el sesgo de la minería de datos tiende a ser mayor, aunque este efecto se reduce cuando el número de valores atípicos positivos es pequeño en relación con el número total de observaciones que se utilizan para calcular la estadística de rendimiento. En otras palabras, un mayor número de observaciones diluye el efecto de sesgo de los valores atípicos positivos.
Si tiene una estrategia cuyo rendimiento se ve afectado por un pequeño número de operaciones, debe prestar atención. En StrategyQuant X hay comprobaciones cruzadas que le ayudarán a hacer frente a este tipo de situaciones
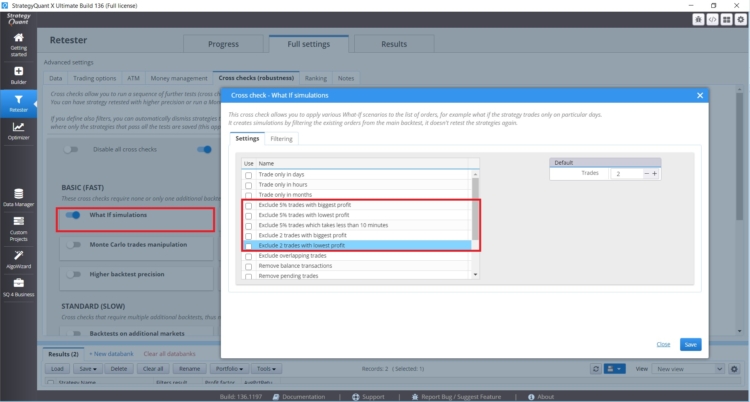
Estos What If Cross Checks le permiten probar el rendimiento de la estrategia sin las operaciones más rentables o las más rentables. Si los resultados de la estrategia son irrazonablemente diferentes, hay que tener cuidado.
-
Variación de los rendimientos esperados entre las normas
[14]Se refiere a la variación del mérito real (rentabilidad esperada) entre las reglas sometidas a prueba. Cuanto menor sea la variación, mayor será el sesgo de la minería de datos. En otras palabras, cuando el conjunto de reglas probadas tiene grados similares de poder predictivo, el sesgo de la minería de datos será mayor.
Este fenómeno puede medirse analizando la variabilidad de los resultados en la base de datos. Según Aronson, cuanto mayor sea la variabilidad de las métricas de rendimiento de la estrategia en el banco de datos, mayor será el riesgo de sesgo de la minería de datos. Para analizar los resultados de todo el banco de datos, puede utilizar un análisis personalizado o exportar la base de datos y analizarla externamente en Excel o Python.
También son dignas de mención las herramientas propuestas para hacer frente a los sesgos de la minería de datos
- Pruebas fuera de la muestra
- Utilización de técnicas de aleatorización
- Pruebas de permutación Monte Carlo
- La realidad blanca
- Métrica de estrategia penalizadora
Desde aquí podemos influir directamente en el tamaño de la muestra y también disponemos de pruebas Monte Carlo directamente en StrategyQuant X.
Conclusión
Desde mi punto de vista, lo más fácil es centrarse en lo siguiente.
- El mayor número posible de operaciones fuera de la muestra.
- Probar múltiples mercados/plazos
- No utilizar todos los métodos posibles al mismo tiempo
- Establecer bloques de construcción según el tipo de estrategias que quiero encontrar
Personalmente, he leído el libro 3 veces en diferentes etapas de mi desarrollo y siempre me ha hecho avanzar. Se ha confirmado en la adopción de una postura crítica hacia diferentes paradigmas en el campo del comercio y los métodos cuantitativos es una buena aunque a veces difícil manera. También puede encontrar muy buenos comentarios en nuestro blog, en artículos sobre entrevistas con operadores, o en el sitio web https://bettersystemtrader.com/.

Notas a pie de página
[1] Página web de los autores, https://www.evidencebasedta.com/
[2] Aronson, D. R. (2021). En Análisis técnico basado en pruebas: Aplicación del método científico y la inferencia estadística a las señales de negociación (pp. 6-6). ensayo, John Wiley & Sons.
[3] https://www.cuemath.com/data/inferential-statistics/
[4]Aronson, D. R. (2021). En Análisis técnico basado en pruebas: Aplicación del método científico y la inferencia estadística a las señales de negociación (pp. 165-165). ensayo, John Wiley & Sons.
[5] Aronson, D. R. (2021). En Análisis técnico basado en pruebas: Aplicación del método científico y la inferencia estadística a las señales de negociación (pp. 264-264). ensayo, John Wiley & Sons.
[6] Aronson, D. R. (2021). En Análisis técnico basado en pruebas: Aplicación del método científico y la inferencia estadística a las señales de negociación (pp. 268-268). ensayo, John Wiley & Sons.
[7] Aronson, D. R. (2021). En Análisis técnico basado en pruebas: Aplicación del método científico y la inferencia estadística a las señales de negociación (pp. 256-256). ensayo, John Wiley & Sons.
[8] Aronson, D. R. (2021). En Análisis técnico basado en pruebas: Aplicación del método científico y la inferencia estadística a las señales de negociación (pp. 280-280). ensayo, John Wiley & Sons.
[9] Fuente: https://en.wikipedia.org/wiki/Multiple_comparisons_problem
[10] Aronson, D. R. (2021). En Análisis técnico basado en pruebas: Aplicación del método científico y la inferencia estadística a las señales de negociación (pp. 289-289). ensayo, John Wiley & Sons.
[11] Aronson, D. R. (2021). En Análisis técnico basado en pruebas: Aplicación del método científico y la inferencia estadística a las señales de negociación (pp. 289-289). ensayo, John Wiley & Sons.
[12] Aronson, D. R. (2021). En Análisis técnico basado en pruebas: Aplicación del método científico y la inferencia estadística a las señales de negociación (pp. 289-289). ensayo, John Wiley & Sons.
[13] Aronson, D. R. (2021). En Análisis técnico basado en pruebas: Aplicación del método científico y la inferencia estadística a las señales de negociación (pp. 289-289). ensayo, John Wiley & Sons.
[14] Aronson, D. R. (2021). En Análisis técnico basado en pruebas: Aplicación del método científico y la inferencia estadística a las señales de negociación (pp. 289-289). ensayo, John Wiley & Sons.

 Ellie Souckova
Ellie Souckova


hola gracias por todo su duro e informativo podría elaborar lo que exactamente su estrategia de penalización métrica es
Excelente revisión del trabajo de Aronson con respecto a StratQuant. Lo que no se explicó explícitamente fue el concepto de "grados de libertad" como se explica en el libro de Robert Pardo, "Design, Testing, and Opimization of Trading Systems," (1992) y su segunda edición, (2008). De la 1ª edición, "Poner demasiadas restricciones a los datos de precios es la principal causa de sobreajuste" pág. 138.
Buen trabajo.