Nel post di oggi cercherò di riassumere alcune idee importanti del libro Evidence Based Technical Analysis di David Aronson. Il libro è stato pubblicato nel 2006 ed è diventato popolare abbastanza rapidamente.
L'Analisi Tecnica Basata sull'Evidenza affronta tematicamente la questione dell'analisi statistica nel contesto dello sviluppo di strategie e la questione del data mining che preoccupa gli utenti. StrategyQuant x è di fatto un sofisticato strumento di data mining che deve essere utilizzato e impostato in modo da ridurre il rischio che la performance della strategia sia in realtà un prodotto del caso.
La prima parte affronta le questioni filosofiche della conoscenza scientifica. Discute l'analisi tecnica e l'analisi come tattica dal punto di vista della filosofia, della metodologia e della logica, e nel complesso si concentra maggiormente sulle questioni teoriche e filosofiche e sulle loro implicazioni per la pratica.
La seconda parte affronta l'uso e le argomentazioni per l'utilizzo di metodi statistici rigorosi, in particolare le statistiche di interferenza, nell'analisi delle prestazioni di una strategia algoritmica. La terza parte affronta ciò che più ci preoccupa come utenti di SQX: le distorsioni del data mining associate ai metodi di confronto multipli. La quarta parte affronta l'uso di vari metodi nel data mining, tra cui l'uso di algoritmi nella ricerca di strategie, l'uso di metodi di conferma nel data mining, ecc.
Questo post del blog ha lo scopo di tirare fuori i concetti di base con cui lavora David Aronson e di applicarli all'argomento dello sviluppo di StrategyQuant X. Mi sono concentrato sulle parti che interessano maggiormente gli utenti di SQX, tenendo conto degli errori più comuni che i neofiti commettono quando configurano il programma.
Cito innanzitutto la breve BIO di David Aronson:
[1]"David Aronson, autore di "Analisi tecnica basata sull'evidenza" (John Wiley & Son 2006) è professore aggiunto di finanza presso la Zicklin School of Business, dove dal 2002 tiene un corso di analisi tecnica e data mining.
Nel 1977, Aronson ha lasciato Merrill Lynch per iniziare uno studio indipendente del nascente campo delle strategie di managed futures e nel 1980 ha fondato AdvoCom Corporation, una società che ha adottato per prima i moderni metodi della teoria del portafoglio e i database computerizzati delle performance per la creazione di portafogli e fondi di futures multi-advisor. Un portafoglio rappresentativo iniziato nel 1984 ha ottenuto un rendimento annuo composto del 23,7%. Nel 1990 AdvoCom ha fornito consulenza a Tudor Investment Corporation per il suo fondo pubblico multi-advisor.
Alla fine degli anni Settanta, mentre conduceva ricerche sulle strategie computerizzate per i managed futures, Aronson intuì il potenziale dell'applicazione dell'intelligenza artificiale alla scoperta di modelli predittivi nei dati dei mercati finanziari. Questa pratica, che oggi si sta affermando a Wall Street, viene chiamata data mining. Nel 1982 Aronson fondò il Raden Research Group, uno dei primi a utilizzare il data mining e la modellazione predittiva non lineare per lo sviluppo di metodi di trading sistematico. L'innovazione di Aronson consisteva nell'applicare il data mining per migliorare le tradizionali strategie di trading computerizzate. Questo approccio è stato descritto per la prima volta nell'articolo di Aronson "Pattern Recognition Signal Filters", Market Technican's Journal - Primavera 1991. Raden Research Group Inc. ha condotto ricerche sulla modellazione predittiva e sullo sviluppo di filtri per conto di diverse società di trading, tra cui Tudor Investment Corporation, Manufacturers Hanover Bank, Transworld Oil, Quantlabs e diversi grandi trader individuali".
Il libro inizia con una definizione dei concetti di base dell'analisi tecnica e cerca di definire l'intero argomento dal punto di vista della logica. Discute questioni filosofiche, metodologiche, statistiche e psicologiche nell'analisi dei mercati finanziari e sottolinea l'importanza del pensiero scientifico, del giudizio e del ragionamento.
Aronson lavora con due definizioni di analisi tecnica
- Analisi tecnica soggettiva (AT)
- Analisi tecnica oggettiva (AT)
L'AT soggettiva, secondo Aronson, non utilizza metodi e procedure scientifiche ripetibili. Si basa sulle interpretazioni personali degli analisti ed è difficile da dimostrare in una prospettiva storica attraverso i backtesting. Al contrario, l'AT l'AT oggettivo si basa sull'uso di metodi di backtesting e sull'uso di un'analisi statistica oggettiva dei risultati del backtesting, secondo Aronson.
L'uso di metodi scientifici nell'analisi tecnico-quantitativa è il tema di fondo dell'intero libro.
[2] "Anche l'AT oggettivo può generare credenze errate, ma queste si verificano in modo diverso. Sono riconducibili a inferenze errate da prove oggettive. Il semplice fatto che un metodo oggettivo sia stato redditizio in un test retrospettivo non è un motivo sufficiente per concludere che sia valido. Le performance passate possono ingannarci. Il successo storico è una condizione necessaria ma non sufficiente per concludere che un metodo ha potere predittivo e, quindi, è probabile che sia redditizio in futuro. Una performance passata favorevole può verificarsi per fortuna o a causa di una tendenza al rialzo prodotta da una forma di backtesting chiamata data mining. Determinare quando i profitti dei backtesting sono attribuibili a un buon metodo piuttosto che alla fortuna è una domanda a cui si può rispondere solo con una rigorosa inferenza statistica".
Aronson critica i metodi di AT soggettivi, ma sottolinea anche che si possono commettere errori anche quando si utilizza un'AT oggettiva.
In questa parte, mi ha interessato molto la parte relativa alle varie forme di errore che sono comuni o che si verificano nella risoluzione di problemi analitici. Tra i metodi di analisi ci sono i cosiddetti biases che si verificano quando si comprendono le cose
- Pregiudizio da eccesso di fiducia
- Bias dell'ottimismo
- Bias di conferma
- Bias di selezione
- Correlazioni illusorie
- Bias dell'ottimismo
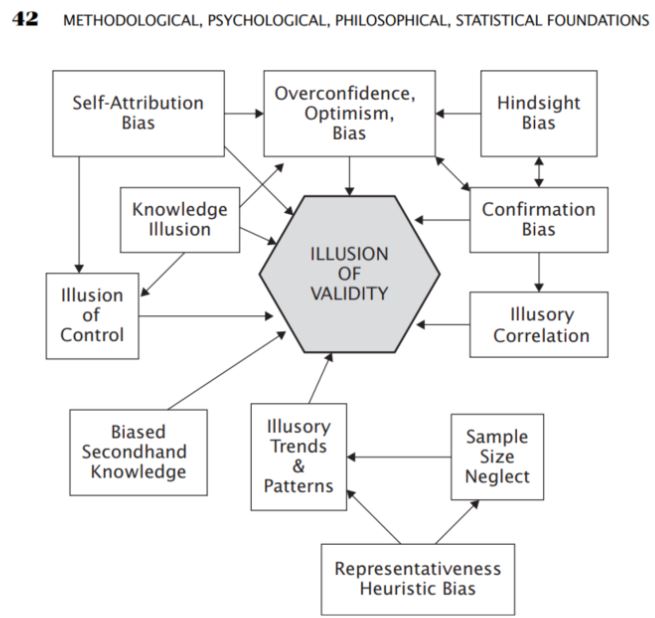
Fonte: Aronson, D. R. (2021). In Analisi tecnica basata sull'evidenza: Applicare il metodo scientifico e l'inferenza statistica ai segnali di trading (pp. 42-42). saggio, John Wiley & Sons.
È l'analisi soggettiva dell'AT che spesso può basarsi sui pregiudizi descritti da Aronson, ma egli sottolinea che anche nell'AT oggettivo-statistico i pregiudizi si verificano spesso inconsciamente. Pertanto, propone l'uso della cosiddetta AT oggettiva sotto forma di applicazione di metodi scientifici nell'analisi.
Aronson riassume le fasi di formulazione delle ipotesi nell'analisi delle interferenze - metodo deduttivo
- Osservazione
- Ipotesi
- Previsione
- Verifica
- Conclusione
Nei capitoli successivi, Aronson spiega l'importanza di un'analisi statistica rigorosa nella valutazione delle strategie.
[3]"La statistica inferenziale aiuta a sviluppare una buona comprensione dei dati della popolazione analizzando i campioni ottenuti da essa. Aiuta a fare generalizzazioni sulla popolazione utilizzando vari test e strumenti analitici. Per selezionare campioni casuali che rappresentino accuratamente la popolazione, si utilizzano molte tecniche di campionamento. Alcuni dei metodi più importanti sono il campionamento casuale semplice, il campionamento stratificato, il campionamento a grappolo e le tecniche di campionamento sistematico".
Aronson lo definisce nel contesto dell'uso dell'analisi tecnica:
[4]"L'identificazione di quali metodi di AT abbiano un reale potere predittivo è altamente incerta. Anche le regole più potenti mostrano prestazioni molto variabili da un set di dati all'altro. Pertanto, l'analisi statistica è l'unico modo pratico per distinguere i metodi utili da quelli che non lo sono. Che i suoi praticanti lo riconoscano o meno, l'essenza della TEA è l'inferenza statistica. Cerca di scoprire generalizzazioni dai dati storici sotto forma di modelli, regole e così via, per poi estrapolarli al futuro. L'estrapolazione è intrinsecamente incerta. L'incertezza è scomoda".
Nel contesto dello sviluppo della strategia in StrategyQuant, X può essere visto come un campione della popolazione.
- Elenco delle compravendite e delle relative metriche di compravendita
- Elenco delle strategie in banca dati e delle relative metriche strategiche
Non voglio emarginare i temi della statistica delle interferenze, dei test d'ipotesi e della statistica descrittiva, ma la loro portata e le loro implicazioni vanno ben oltre lo scopo di questo articolo, quindi
Vi consiglio di consultare queste risorse:
Estrazione dei dati
[5]Il data mining è l'estrazione di conoscenza, sotto forma di schemi, regole, modelli, funzioni e simili, da grandi database.
Per noi utenti di StrategyQuant X, è probabile che utilizziamo qualche forma di data mining nella nostra ricerca di strategie redditizie.
Con StrategyQuant X, in genere utilizziamo il data mining quando siamo alla ricerca di
- Ricerca strategica ( Costruttore )
- Ottimizzazione della strategia ( Ottimizzazione )
Aronson cita le differenze tra lo sviluppo classico della strategia e il data mining:
- Consideriamo il metodo classico come quello in cui uno sviluppatore crea un strategia da zero senza utilizzare metodi di data mining. Nel contesto dell'StrategyQuant X, potremmo pensare alla creazione manuale di strategie in Algowizard, dove possiamo creare strategie secondo la nostra logica.
- Quando si utilizza il data mining, testiamo un gran numero di regole per trovare la strategia con la più alta performance osservata e la più alta probabilità di performance futura.
Aronson sostiene l'uso del data mining come segue:
-
[6]Innanzitutto, funziona. Gli esperimenti presentati più avanti in questo capitolo dimostreranno che, in condizioni abbastanza generali, maggiore è il numero di regole testate, maggiore è la probabilità di trovare una buona regola.
-
In secondo luogo, le tendenze tecnologiche favoriscono il data mining. L'economicità dei personal computer, la disponibilità di potenti software di back-testing e data-mining e la disponibilità di database storici rendono il data mining pratico per i privati. Fino a un decennio fa, i costi limitavano il data mining agli investitori istituzionali.
-
In terzo luogo, nel suo attuale stadio evolutivo, l'AT manca del fondamento teorico che consentirebbe un approccio scientifico più tradizionale all'acquisizione della conoscenza.
Pregiudizio dell'estrazione dei dati
Aronson sostiene che le distorsioni nell'estrazione dei dati potrebbero essere una delle ragioni principali del fallimento delle strategie nel trading fuori campione o reale.
[7]"Data-mining bias: la differenza attesa tra la performance osservata della regola migliore e la sua performance attesa. La differenza attesa si riferisce a una differenza media di lungo periodo che si otterrebbe con numerosi esperimenti che misurano la differenza tra il rendimento osservato della regola migliore e il rendimento atteso della regola migliore".
Considera le due componenti principali della performance osservata (performance della strategia) come segue.
- Prevedibilità della strategia
- Casualità - Fortuna
[8]"Ora arriviamo a un principio importante. Quanto maggiore è il contributo della casualità (fortuna) rispetto al merito nella performance osservata (risultati dei backtest), tanto maggiore sarà l'entità del bias di estrazione dei dati. Il motivo è questo: Maggiore è il ruolo della fortuna rispetto al merito, maggiore è la possibilità che una delle molte regole candidate (strategie) registri una performance straordinariamente fortunata. Questo è il candidato che verrà selezionato dal data miner. Tuttavia, nelle situazioni in cui le prestazioni osservate sono strettamente o principalmente dovute al vero merito di un candidato, il bias del data mining sarà inesistente o molto ridotto. In questi casi, le prestazioni passate di un candidato saranno un indicatore affidabile delle prestazioni future e il data miner riempirà raramente la tramoggia con l'oro degli sciocchi. Poiché i mercati finanziari sono estremamente difficili da prevedere, la maggior parte della performance osservata di una regola sarà dovuta alla casualità piuttosto che al suo potere predittivo. "
Nel contesto della strategia Quant X, possiamo dire che l'elemento del caso è associato all'atteggiamento più benevolo di StrategyQuant X. ISe scegliamo troppe combinazioni quando cerchiamo le strategie, StrategyQuant X può trovarne una che ha un backtest positivo ma non funziona nella realtà della strategia. Qui di seguito, alla fine del post, sono riassunti i fattori che influenzano questa casualità, con suggerimenti per la configurazione dell'StrategyQuant X.
Molta attenzione viene prestata anche alla procedura di confronto multiplo (MCP). Wikipedia definisce le procedure di confronto multiplo come :
[9]"I confronti multipli si verificano quando un'analisi statistica coinvolge più test statistici simultanei, ognuno dei quali ha il potenziale di produrre una "scoperta". Un livello di confidenza dichiarato si applica generalmente solo a ciascun test considerato singolarmente, ma spesso è auspicabile avere un livello di confidenza per l'intera famiglia di test simultanei".
Nel contesto di StrategyQuant X, possiamo applicare il problema dei confronti multipli ogni volta che cerchiamo un gran numero di indicatori/condizioni/impostazioni di una particolare strategia in un ampio spettro. Utilizzando i metodi dei confronti multipli, possiamo facilmente determinare che la soluzione trovata, nel nostro caso la strategia e la sua performance fuori dal campione, è il risultato del caso e di un gran numero di combinazioni testate. Più regole e più variabilità vengono utilizzate nel setup di SQX, più alta è la probabilità che la performance della strategia in OS sia frutto del caso e quindi più alta è la probabilità che la strategia fallisca nel trading reale.
Aronson dimostra le conclusioni presentate nella sezione seguente eseguendo sperimentalmente le regole di trading basate sui dati per l'indice S&P 500 nel periodo compreso tra il 1328 e il 2003. La procedura esatta si trova a pagina 292. Un esperimento simile può essere facilmente ripetuto in StrategyQuant X per qualsiasi mercato.
5 fattori che influenzano il grado di distorsione del data mining
-
Numero di regole testate a posteriori:
[10]"Si riferisce al numero totale di regole testate durante il processo di data-mining per scoprire la regola più performante. Maggiore è il numero di regole testate, maggiore è la distorsione del data-mining".
Implicazioni Numero di regole testate a posteriori durante lo sviluppo di strategie in StrategyQuant X
Il numero di regole utilizzate nella ricerca della strategia può essere influenzato in StrategyQuant X dalle seguenti impostazioni in Costruttore/ Cosa costruire:
- Intervallo dei parametri (periodi)
- Periodo di attesa
- Impostazioni degli stop loss e degli obiettivi Profit
- Impostare il numero massimo di regole in caso di entrata e uscita.
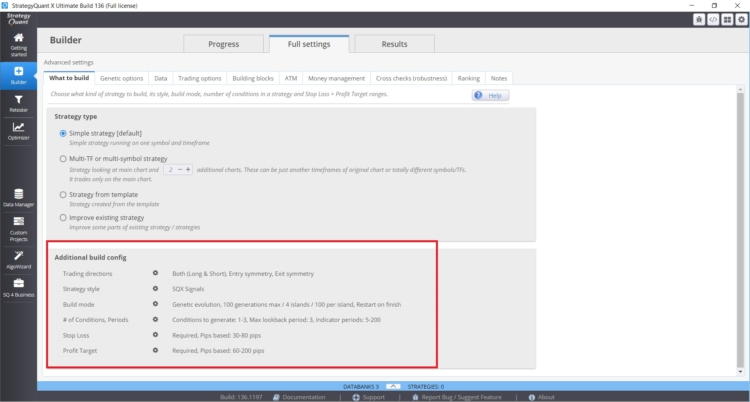
In questo caso, più grandi sono i valori e gli intervalli specificati, maggiore è il rischio di distorsioni da data mining.. Una buona pratica è quella di utilizzare un massimo di due regole di input, mentre per il periodo di loopback mi atterrei a un valore massimo di 3. Spesso vedo da parte dei clienti strategie con 6 condizioni e periodi di lookback di 25. Queste combinazioni comportano un rischio reale di distorsione da data mining.
Se si desidera impostare periodi di lookback specifici per blocchi specifici dove ha senso (chiusura giornaliera, ecc.), è possibile impostarli direttamente per una regola specifica, come si può vedere nella figura seguente:
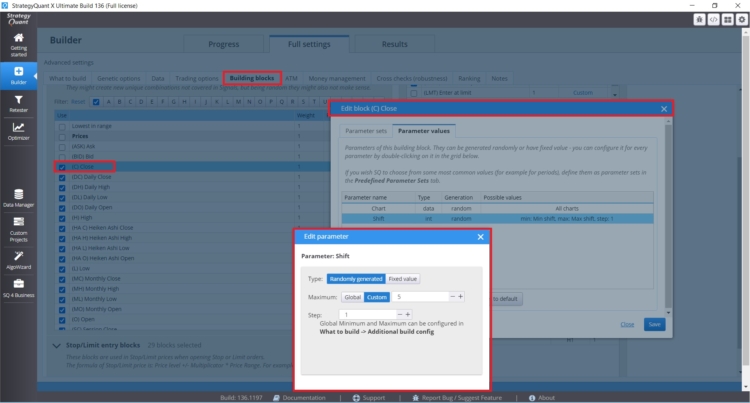
È inoltre possibile controllare direttamente i tipi, le quantità e le impostazioni dei blocchi di costruzione nella scheda Costruttore con Indici/Regole di entrata.
Numero di indicatori, condizioni e blocchi di confronto:
- Numero di blocchi di ingresso possibili
- Numero di blocchi di uscita possibili
- Nel caso di ordini Stop/Limit è importante il numero di indicatori stop limit.
- Tipi di uscite e ingressi e relative impostazioni.
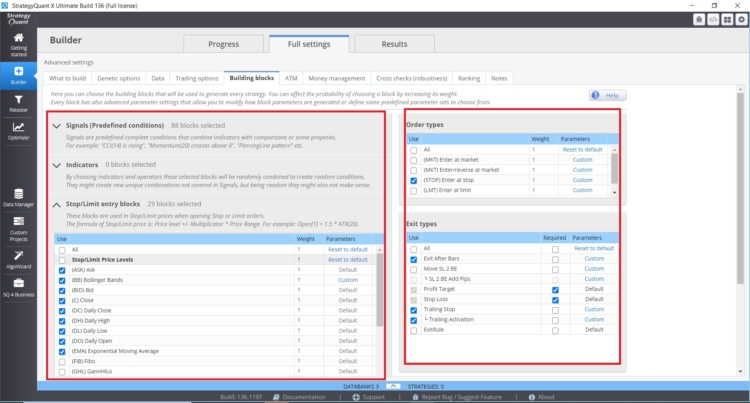
Più opzioni inseriamo nel motore genetico StrategyQuant X, maggiore può essere la distorsione del data mining.
-
Numero di osservazioni utilizzate per calcolare la statistica di performance:
[11]Maggiore è il numero di osservazioni, minore è il bias di estrazione dei dati.
Implicazioni del numero di osservazioni nello sviluppo della strategia in StrategyQuant X:
In generale, più grande è il campione di dati (numero di operazioni in uscita dal campione), maggiore è la potenza statistica dei risultati.
Questo obiettivo può essere raggiunto attraverso:
- Dati fuori campione più grandi = dimensione del campione più grande
- Più mercati testati = dimensione del campione più ampia
- Più intervalli di tempo testati = dimensione del campione più ampia
Inoltre, dal punto di vista delle statistiche di interferenza, gli indicatori di strategia identificati hanno un valore predittivo più elevato quando il campione è sufficientemente ampio Analogamente, le statistiche di strategia identificate hanno un peso maggiore quando la dimensione del campione identificato è maggiore. Va sottolineato che non è necessario considerare i risultati in-sample se le prestazioni out-of-sample della strategia sono di maggior valore. Tuttavia, anche questo aspetto è influenzato dalle distorsioni dell'estrazione dei dati associate alla procedura di confronto multiplo. In pratica, ciò può significare che la performance effettiva è molto probabilmente peggiore di quella del backtest fuori campione.
Questo punto è considerato da Aronson il più importante di tutti i fattori. Egli sostiene che quanto più ampio è il campione di dati ottenuti, tanto minore è l'impatto negativo degli altri fattori. Quando si ottimizza una strategia esistente, prestare attenzione agli intervalli dei parametri e al numero di passi. In generale, maggiore è il numero di opzioni, maggiore è la possibilità di azzardo.
Come impostare l'intervallo di backtest e il periodo fuori campione in StrategyQuant X
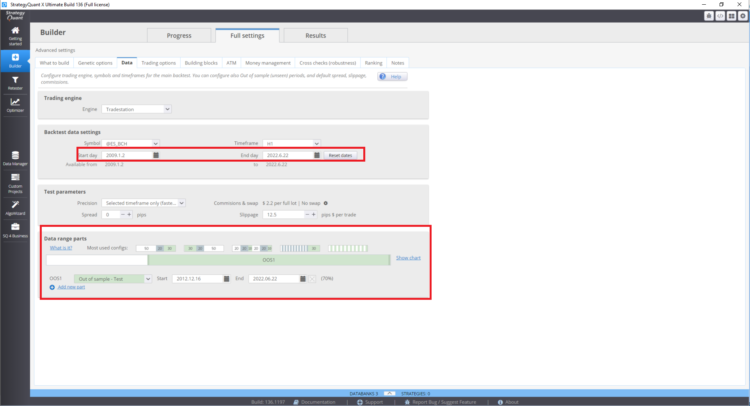
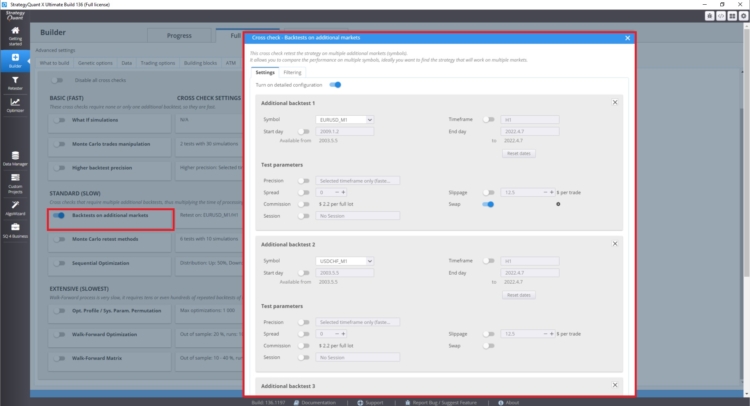
Come impostare i test multi-mercato
Nella sezione Controlli incrociati, alla voce Backtest su altri mercati, è possibile impostare i backtest su altri mercati.
Dove impostare la funzione di fitness e il ranking vero in StrategyQuant X
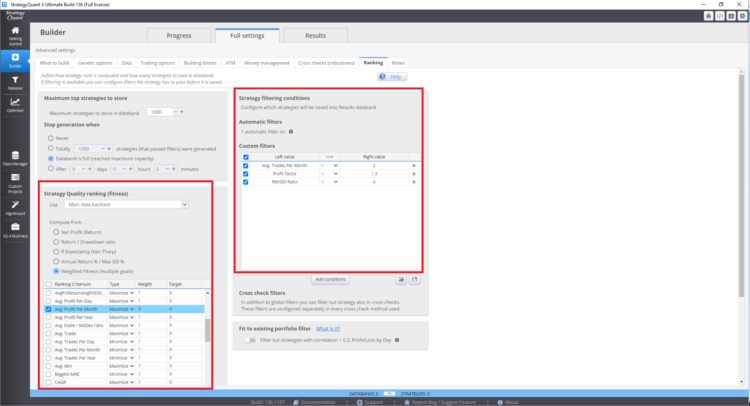
Queste impostazioni possono influenzare le strategie risultanti nella banca dati.
-
Correlazione tra i rendimenti delle regole
[12]Si riferisce al grado di correlazione tra gli storici delle prestazioni delle regole testate. Minore è la correlazione, maggiore è l'errore di estrazione dei dati.
Più forte è la correlazione tra le regole testate, minore sarà l'entità del bias. Al contrario, quanto più bassa è la correlazione (ovvero, quanto maggiore è il grado di indipendenza statistica) tra le regole restituite, tanto più grande sarà il bias di data-mining. Questo ha senso perché l'aumento della correlazione tra le regole ha la conseguenza di ridurre il numero effettivo di regole da sottoporre a back-testing.
Questo punto è difficile da comprendere. Si basa sulla conoscenza del primo punto. Il numero di strategie correlate nell'StrategyQuantX può essere influenzato dal tipo di blocchi di costruzione utilizzati nella costruzione delle strategie, ma anche dall'impostazione della ricerca genetica delle strategie. Ad esempio, se si scelgono solo le medie mobili come elementi costitutivi, è più probabile che le strategie siano più correlate tra loro.
Se il numero di blocchi di costruzione è molto basso, non si realizzerà il potenziale del data mining; al contrario, se il numero di blocchi di costruzione è molto alto, si rischia un grande bias di data mining. Questi fattori possono essere eliminati da un numero elevato di operazioni o da test su più mercati.
È possibile gestire queste impostazioni in Opzioni del costruttore/genetica.
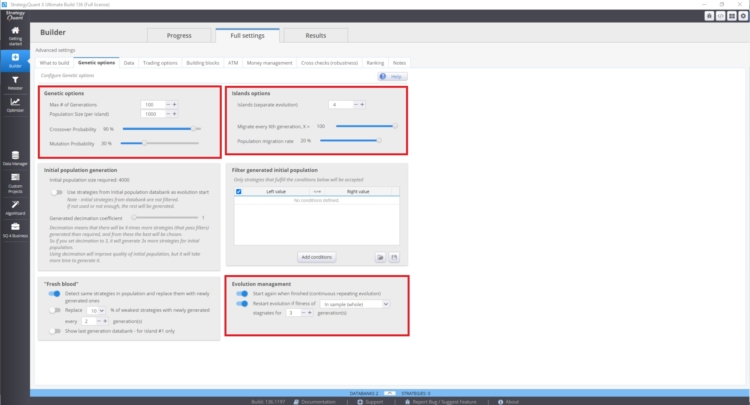
La velocità di convergenza della curva di fitness e la variabilità delle strategie dipendono da:
- Valore più alto della probabilità di crossover
- Valore inferiore della probabilità di mutazione
Anche l'evoluzione delle isole può avere un impatto importante. Questo prevede la migrazione di strategie tra le isole. Anche la gestione evolutiva può svolgere un ruolo importante. Soprattutto se si riavvia l'evoluzione genetica con un numero eccessivo di generazioni. Si potrebbe finire per avere più strategie correlate nella banca dati.
Queste impostazioni possono essere in contraddizione tra loro e il loro utilizzo dipende dal caso specifico. Questo problema non è facile da capire, perché lo stato del database dipende da molti fattori.
-
Presenza di rendimenti anomali positivi
[13]Si tratta della presenza di rendimenti molto elevati nella storia delle performance di una regola, ad esempio un rendimento positivo molto elevato in un particolare giorno. In questi casi, il bias di estrazione dei dati tende a essere maggiore, anche se questo effetto si riduce quando il numero di outlier positivi è ridotto rispetto al numero totale di osservazioni utilizzate per calcolare la statistica di performance. In altre parole, un maggior numero di osservazioni diluisce l'effetto distorsivo degli outlier positivi.
Se avete una strategia le cui prestazioni sono influenzate da un numero ridotto di operazioni, dovete prestare attenzione. In StrategyQuant X sono presenti controlli incrociati What-if che vi aiuteranno a gestire tali situazioni.
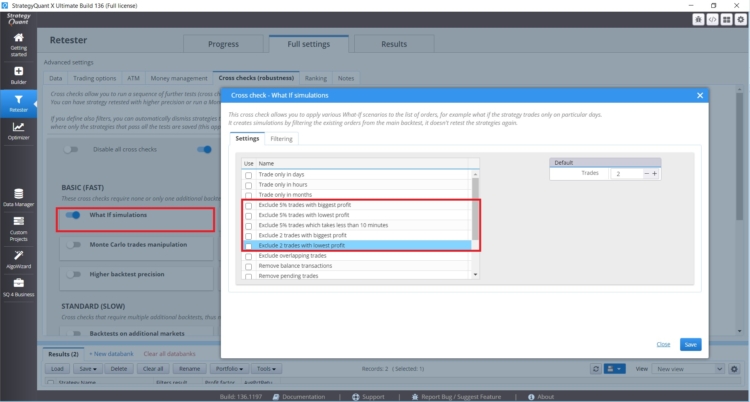
Questi controlli incrociati consentono di testare le prestazioni della strategia senza le operazioni più redditizie o quelle più redditizie. Se i risultati della strategia sono irragionevolmente diversi, bisogna fare attenzione.
-
Variazione dei rendimenti attesi tra le regole
[14]Si riferisce alla variazione del merito reale (rendimento atteso) tra le regole testate in precedenza. Minore è la variazione, maggiore è il bias di data-mining. In altre parole, quando l'insieme delle regole testate ha gradi simili di potere predittivo, il bias di data-mining sarà maggiore.
Questo fenomeno può essere misurato analizzando la variabilità dei risultati nel database. Secondo Aronson, maggiore è la variabilità delle metriche delle prestazioni strategiche nella banca dati, maggiore è il rischio di distorsione del data mining. Per analizzare i risultati dell'intera banca dati, è possibile utilizzare un'analisi personalizzata o esportare la banca dati e analizzarla esternamente in Excel o Python.
Vale la pena menzionare anche gli strumenti proposti per gestire i pregiudizi del data mining.
- Test fuori campione
- Uso di tecniche di randomizzazione
- Test di permutazione Monte Carlo
- Controllo della realtà bianca
- Strategia di penalizzazione metrica
Da qui possiamo influenzare direttamente la dimensione del campione e abbiamo anche test Monte Carlo disponibili direttamente in StrategyQuant X.
Conclusione
Dal mio punto di vista, la cosa più semplice da fare è concentrarsi su quanto segue.
- Il maggior numero possibile di operazioni fuori campione.
- Test su più mercati/quadri temporali
- Non utilizzare tutti i metodi possibili contemporaneamente
- Impostazione dei blocchi di costruzione in base al tipo di strategie che voglio trovare
Personalmente, ho letto il libro 3 volte in diverse fasi del mio sviluppo e mi ha sempre fatto progredire. Mi ha confermato che assumere una posizione critica nei confronti dei diversi paradigmi nel campo del trading e dei metodi quantitativi è una strada buona, anche se a volte difficile. Ottimi spunti di riflessione si possono trovare anche sul nostro blog negli articoli dedicati alle interviste ai trader o sul sito https://bettersystemtrader.com/.

Note a piè di pagina
[1] Sito web degli autori, https://www.evidencebasedta.com/
[2] Aronson, D. R. (2021). In Analisi tecnica basata sull'evidenza: Applicare il metodo scientifico e l'inferenza statistica ai segnali di trading (pp. 6-6). saggio, John Wiley & Sons.
[3] https://www.cuemath.com/data/inferential-statistics/
[4]Aronson, D. R. (2021). In Analisi tecnica basata sull'evidenza: Applicare il metodo scientifico e l'inferenza statistica ai segnali di trading (pp. 165-165). saggio, John Wiley & Sons.
[5] Aronson, D. R. (2021). In Analisi tecnica basata sull'evidenza: Applicare il metodo scientifico e l'inferenza statistica ai segnali di trading (pp. 264-264). saggio, John Wiley & Sons.
[6] Aronson, D. R. (2021). In Analisi tecnica basata sull'evidenza: Applicare il metodo scientifico e l'inferenza statistica ai segnali di trading (pp. 268-268). saggio, John Wiley & Sons.
[7] Aronson, D. R. (2021). In Analisi tecnica basata sull'evidenza: Applicare il metodo scientifico e l'inferenza statistica ai segnali di trading (pp. 256-256). saggio, John Wiley & Sons.
[8] Aronson, D. R. (2021). In Analisi tecnica basata sull'evidenza: Applicare il metodo scientifico e l'inferenza statistica ai segnali di trading (pp. 280-280). saggio, John Wiley & Sons.
[9] Fonte: https://en.wikipedia.org/wiki/Multiple_comparisons_problem
[10] Aronson, D. R. (2021). In Analisi tecnica basata sull'evidenza: Applicare il metodo scientifico e l'inferenza statistica ai segnali di trading (pp. 289-289). saggio, John Wiley & Sons.
[11] Aronson, D. R. (2021). In Analisi tecnica basata sull'evidenza: Applicare il metodo scientifico e l'inferenza statistica ai segnali di trading (pp. 289-289). saggio, John Wiley & Sons.
[12] Aronson, D. R. (2021). In Analisi tecnica basata sull'evidenza: Applicare il metodo scientifico e l'inferenza statistica ai segnali di trading (pp. 289-289). saggio, John Wiley & Sons.
[13] Aronson, D. R. (2021). In Analisi tecnica basata sull'evidenza: Applicare il metodo scientifico e l'inferenza statistica ai segnali di trading (pp. 289-289). saggio, John Wiley & Sons.
[14] Aronson, D. R. (2021). In Analisi tecnica basata sull'evidenza: Applicare il metodo scientifico e l'inferenza statistica ai segnali di trading (pp. 289-289). saggio, John Wiley & Sons.

 Ellie Souckova
Ellie Souckova


Ciao, grazie per tutti i tuoi sforzi e le tue informazioni, potresti elaborare cosa è esattamente la tua strategia di penalizzazione metrica
Eccellente recensione del lavoro di Aronson in relazione a StratQuant. Ciò che non è stato spiegato esplicitamente è il concetto di "gradi di libertà" come spiegato nel libro di Robert Pardo, "Design, Testing, and Opimization of Trading Systems" (1992) e nella sua seconda edizione (2008). Dalla prima edizione, "Porre troppe restrizioni ai dati di prezzo è la causa principale dell'overfitting", pag. 138.
Ottimo lavoro.