Dans le billet d'aujourd'hui, je vais essayer de résumer quelques idées importantes du livre Evidence Based Technical Analysis de David Aronson. Ce livre a été publié en 2006 et est devenu populaire assez rapidement.
L'analyse technique fondée sur des données probantes aborde de manière thématique la question de l'analyse statistique dans le contexte de l'élaboration d'une stratégie et la question de l'exploration de données qui préoccupe les utilisateurs. StrategyQuant x est de facto un outil sophistiqué d'exploration de données qui doit être déployé et configuré de manière à réduire le risque que la performance de la stratégie soit en fait un produit du hasard.
La première partie traite des questions philosophiques de la connaissance scientifique. Elle aborde l'analyse technique et l'analyse en tant que tactique du point de vue de la philosophie, de la méthodologie et de la logique, et se concentre davantage sur les questions théoriques et philosophiques et leurs implications pour la pratique.
La deuxième partie traite de l'utilisation et des arguments en faveur de l'utilisation de méthodes statistiques rigoureuses, en particulier les statistiques d'interférence, dans l'analyse des performances d'une stratégie algorithmique. La troisième partie aborde ce qui pourrait nous préoccuper le plus en tant qu'utilisateurs de SQX, à savoir les biais de data mining associés aux méthodes de comparaison multiple. La quatrième partie aborde l'utilisation de diverses méthodes dans le data mining, y compris l'utilisation d'algorithmes dans la recherche de stratégies, l'utilisation de méthodes de confirmation dans le data mining, etc.
Ce billet de blog a pour but de présenter les concepts de base avec lesquels David Aronson travaille et de les appliquer au sujet du développement de StrategyQuant X. Je me suis concentré sur les parties qui concernent le plus les utilisateurs de SQX, en tenant compte des erreurs les plus courantes que les débutants commettent lors de la configuration du programme.
Je cite tout d'abord la courte biographie de David Aronson :
[1]"David Aronson, auteur de "Evidence-Based Technical Analysis" (John Wiley & Son's 2006) est professeur adjoint de finance à la Zicklin School of Business, où il enseigne depuis 2002 un cours d'analyse technique et d'exploration de données au niveau du troisième cycle.
En 1977, Aronson a quitté Merrill Lynch pour entreprendre une étude indépendante du domaine naissant des stratégies de gestion des contrats à terme et, en 1980, il a créé AdvoCom Corporation, qui a adopté très tôt les méthodes modernes de la théorie du portefeuille et les bases de données informatisées sur les performances pour la création de portefeuilles et de fonds de contrats à terme multi-conseillers. Un portefeuille représentatif créé en 1984 a obtenu un rendement annuel composé de 23,7%. En 1990, AdvoCom a conseillé Tudor Investment Corporation pour son fonds public multi-conseillers.
À la fin des années soixante-dix, alors qu'il menait des recherches sur les stratégies informatisées de gestion des contrats à terme, Aronson a réalisé qu'il était possible d'appliquer l'intelligence artificielle à la découverte de modèles prédictifs dans les données des marchés financiers. Cette pratique, qui est aujourd'hui de plus en plus acceptée à Wall Street, est connue sous le nom de "data mining" (exploration de données). En 1982, Aronson a fondé le Raden Research Group, qui a été l'un des premiers à adopter l'exploration de données et la modélisation prédictive non linéaire pour le développement de méthodes de négociation systématique. L'innovation d'Aronson consistait à appliquer l'exploration de données pour améliorer les stratégies de négociation informatisées traditionnelles. Cette approche a été décrite pour la première fois dans l'article d'Aronson, "Pattern Recognition Signal Filters", Market Technican's Journal - printemps 1991. Raden Research Group Inc. a mené des recherches sur la modélisation prédictive et le développement de filtres pour le compte de diverses sociétés de négoce, notamment Tudor Investment Corporation, Manufacturers Hanover Bank, Transworld Oil, Quantlabs et plusieurs grands négociants individuels.
Le livre commence par une définition des concepts de base de l'analyse technique et tente de définir l'ensemble du sujet du point de vue de la logique. Il aborde les questions philosophiques, méthodologiques, statistiques et psychologiques de l'analyse des marchés financiers et souligne l'importance de la pensée scientifique, du jugement et du raisonnement.
Aronson utilise deux définitions de l'analyse technique
- Analyse technique subjective (AT)
- Analyse technique objective (AT)
Selon Aronson, l'AT subjective n'utilise pas de méthodes et de procédures scientifiques reproductibles. Elle se fonde sur les interprétations personnelles des analystes et est difficile à prouver d'un point de vue historique par le biais de tests rétrospectifs. En revanche, l l'AT objective est basée sur l'utilisation de méthodes de backtesting et sur l'utilisation d'une analyse statistique objective des résultats du backtestingselon Aronson.
L'utilisation de méthodes scientifiques dans l'analyse technique/quantitative est le thème de base de l'ensemble de l'ouvrage.
[2] "L'AT objective peut également engendrer des croyances erronées, mais celles-ci se produisent différemment. Elles sont dues à des déductions erronées à partir de preuves objectives. Le simple fait qu'une méthode objective ait été rentable lors d'un test rétrospectif n'est pas suffisant pour conclure à son bien-fondé. Les performances passées peuvent nous tromper. La réussite historique est une condition nécessaire mais non suffisante pour conclure qu'une méthode a un pouvoir prédictif et qu'elle est donc susceptible d'être rentable à l'avenir. Des performances passées favorables peuvent être dues à la chance ou à un biais à la hausse produit par une forme de backtesting appelée "data mining" (exploration de données). Déterminer quand les bénéfices d'un backtesting sont attribuables à une bonne méthode plutôt qu'à la chance est une question à laquelle on ne peut répondre que par une inférence statistique rigoureuse".
Aronson critique les méthodes d'AT subjectives mais souligne également que des erreurs peuvent être commises même lors de l'utilisation d'une AT objective.
Dans cette partie, j'ai été très intéressée par la partie concernant les différentes formes d'erreurs qui sont courantes ou qui se produisent lors de la résolution de problèmes analytiques. Parmi les méthodes d'analyse, il y a ce qu'on appelle les biais qui se produisent lorsqu'on comprend les choses
- Biais d'excès de confiance
- Biais d'optimisme
- Biais de confirmation
- Biais de sélection
- Corrélations illusoires
- Biais d'optimisme
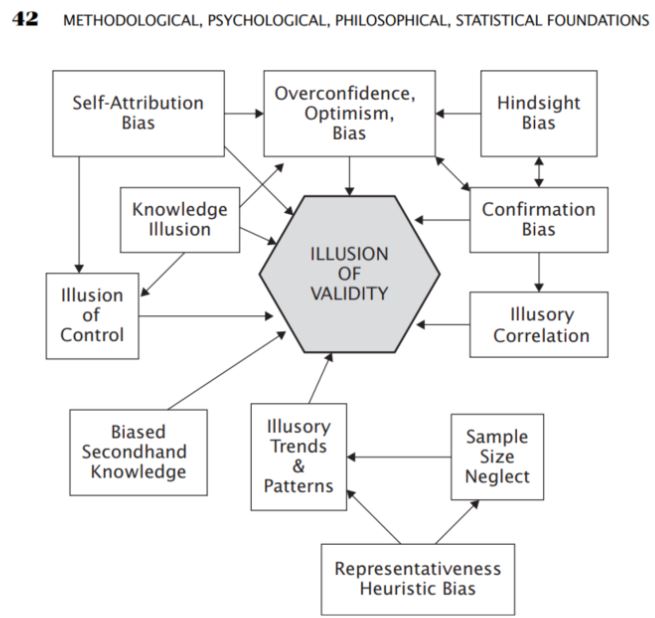
Source : Aronson, D. R. (2021). Dans L'analyse technique fondée sur des données probantes : L'application de la méthode scientifique et de l'inférence statistique aux signaux de trading (pp. 42-42). essai, John Wiley & Sons.
C'est l'analyse subjective de l'AT qui peut souvent être basée sur les biais décrits par Aronson, mais il souligne que même avec l'AT objective et statistique, les biais se produisent souvent de manière inconsciente. Il propose donc l'utilisation de l'AT dite objective sous la forme de l'application de méthodes scientifiques dans l'analyse.
Aronson résume les étapes de la formulation d'une hypothèse dans l'analyse de l'interférence - méthode déductive
- Observation
- Hypothèse
- Prédiction
- Vérification
- Conclusion
Dans les chapitres suivants, Aronson explique l'importance d'une analyse statistique rigoureuse pour évaluer les stratégies.
[3]"Les statistiques inférentielles aident à développer une bonne compréhension des données de la population en analysant les échantillons obtenus à partir de celle-ci. Elle aide à faire des généralisations sur la population en utilisant divers tests et outils analytiques. De nombreuses techniques d'échantillonnage sont utilisées pour sélectionner des échantillons aléatoires qui représenteront la population avec précision. Parmi les méthodes les plus importantes, citons l'échantillonnage aléatoire simple, l'échantillonnage stratifié, l'échantillonnage en grappes et les techniques d'échantillonnage systématique".
Aronson la définit dans le contexte de l'utilisation de l'analyse technique :
[4]"L'identification des méthodes d'AT qui ont un véritable pouvoir prédictif est très incertaine. Même les règles les plus puissantes affichent des performances très variables d'un ensemble de données à l'autre. Par conséquent, l'analyse statistique est le seul moyen pratique de distinguer les méthodes qui sont utiles de celles qui ne le sont pas. Que ses praticiens le reconnaissent ou non, l'essence de l'AET est l'inférence statistique. Elle tente de découvrir des généralisations à partir de données historiques sous la forme de modèles, de règles, etc. et de les extrapoler à l'avenir. L'extrapolation est intrinsèquement incertaine. L'incertitude est inconfortable".
Dans le contexte du développement de la stratégie dans StrategyQuant, X peut être considéré comme un échantillon de la population.
- Liste des transactions et de leurs paramètres
- Liste des stratégies dans la banque de données et leurs mesures stratégiques
Je ne veux pas marginaliser les thèmes des statistiques d'interférence, des tests d'hypothèse et des statistiques descriptives, mais leur portée et leurs implications dépassent largement le cadre de cet article.
Je vous recommande de consulter ces ressources :
Exploration de données
[5]L'exploration de données est l'extraction de connaissances, sous forme de modèles, de règles, de fonctions, etc., à partir de grandes bases de données.
En tant qu'utilisateurs de StrategyQuant X, nous utilisons probablement une certaine forme de data mining dans notre recherche de stratégies rentables.
Avec StrategyQuant X, nous utilisons généralement le data mining lorsque nous recherchons
- Recherche de stratégie ( Builder )
- Optimisation de la stratégie ( Optimisation )
Aronson mentionne les différences entre l'élaboration d'une stratégie classique et l'exploration de données :
- Nous considérons que la méthode classique est celle dans laquelle un développeur crée un à partir de zéro sans utiliser de méthodes d'exploration de données. Dans le contexte de StrategyQuant X, nous pourrions penser à la création manuelle de stratégies dans Algowizard, où nous pouvons créer des stratégies selon notre logique.
- Lors de l'utilisation de l'exploration de données, nous testons un grand nombre de règles pour trouver la stratégie ayant la plus grande performance observée et la plus grande probabilité de performance future.
Aronson plaide en faveur de l'utilisation du data mining de la manière suivante :
-
[6]Tout d'abord, cela fonctionne. Les expériences présentées plus loin dans ce chapitre montrent que, dans des conditions relativement générales, plus le nombre de règles testées est élevé, plus la probabilité de trouver une bonne règle est grande.
-
Deuxièmement, les tendances technologiques favorisent l'exploration de données. La rentabilité des ordinateurs personnels, la disponibilité de puissants logiciels de back-testing et d'exploration de données, ainsi que la disponibilité de bases de données historiques, rendent aujourd'hui l'exploration de données pratique pour les particuliers. Il y a encore dix ans, les coûts limitaient l'exploration de données aux investisseurs institutionnels.
-
Troisièmement, à son stade actuel d'évolution, l'AT ne dispose pas des fondements théoriques qui permettraient une approche scientifique plus traditionnelle de l'acquisition des connaissances
Biais dans l'exploration des données
Aronson affirme que les biais dans l'exploration des données pourraient être une raison majeure de l'échec des stratégies dans les transactions hors échantillon ou réelles.
[7]"Biais d'exploration des données : différence attendue entre la performance observée de la meilleure règle et sa performance attendue. La différence attendue fait référence à une différence moyenne à long terme qui serait obtenue par de nombreuses expériences mesurant la différence entre le rendement observé de la meilleure règle et le rendement attendu de la meilleure règle".
Il considère les deux principales composantes de la performance observée (performance de la stratégie) comme suit.
- Prévisibilité de la stratégie
- Hasard - Chance
[8]"Nous arrivons maintenant à un principe important. Plus la contribution du hasard (de la chance) est importante par rapport au mérite dans les performances observées (résultats des backtests), plus l'ampleur du biais d'exploration des données sera importante. La raison en est la suivante : Plus le rôle de la chance est important par rapport au mérite, plus il y a de chances que l'une des nombreuses règles ( stratégies ) candidates connaisse une performance extraordinairement chanceuse. C'est ce candidat qui sera sélectionné par le data miner. Toutefois, dans les situations où la performance observée est strictement ou principalement due au mérite réel d'un candidat, le biais d'exploration des données sera inexistant ou très faible. Dans ces cas, les performances passées d'un candidat seront un indicateur fiable de ses performances futures et le data miner remplira rarement la trémie avec de l'or du fou. Les marchés financiers étant extrêmement difficiles à prévoir, la plupart des performances observées d'une règle seront dues au hasard plutôt qu'à son pouvoir prédictif. "
Dans le contexte de Strategy Quant X, nous pouvons dire que l'élément de hasard est associé à l'attitude plus bienveillante de StrategyQuant X. Ii nous choisissons trop de combinaisons lors de la recherche de stratégies, StrategyQuant X peut en trouver une qui a un backtest positif mais qui ne fonctionne pas dans la réalité de la stratégie. Ci-dessous, à la fin de l'article, les facteurs qui influencent ce caractère aléatoire sont résumés avec des conseils dans la configuration de StrategyQuant X.
La procédure de comparaison multiple (PCM) fait également l'objet d'une grande attention. Wikipedia définit les procédures de comparaison multiple comme suit :
[9]"Les comparaisons multiples surviennent lorsqu'une analyse statistique implique plusieurs tests statistiques simultanés, chacun d'entre eux étant susceptible de produire une "découverte". Le niveau de confiance indiqué ne s'applique généralement qu'à chaque test considéré individuellement, mais il est souvent souhaitable de disposer d'un niveau de confiance pour l'ensemble des tests simultanés".
Dans le contexte de StrategyQuant X, nous pouvons appliquer le problème des comparaisons multiples lorsque nous recherchons un grand nombre d'indicateurs/conditions/réglages d'une stratégie particulière dans un large spectre. En utilisant les méthodes de comparaisons multiples, nous pouvons facilement déterminer que la solution trouvée, dans notre cas la stratégie et sa performance hors échantillon, est le résultat du hasard et d'un grand nombre de combinaisons testées. Plus il y a de règles et de variabilité dans la configuration du SQX, plus la probabilité que la performance de la stratégie dans l'OS soit un produit du hasard est élevée et, par conséquent, plus la probabilité que la stratégie échoue dans le trading réel est élevée.
Aronson prouve les conclusions présentées dans la section suivante en appliquant de manière expérimentale les règles de trading basées sur les données pour l'indice S&P 500 sur la période allant de 1328 à 2003. La procédure exacte est décrite à la page 292. Une expérience similaire peut être facilement répétée dans StrategyQuant X pour n'importe quel marché.
5 Facteurs influençant le degré de biais de l'exploration de données
-
Nombre de règles ayant fait l'objet d'un contrôle a posteriori :
[10]"Il s'agit du nombre total de règles testées au cours du processus d'exploration des données en vue de découvrir la règle la plus performante. Plus le nombre de règles testées est élevé, plus le biais d'exploration des données est important".
Implications Nombre de règles testées lors de l'élaboration de stratégies dans StrategyQuant X
Le nombre de règles utilisées dans la recherche de stratégie peut être influencé dans StrategyQuant X dans les paramètres suivants dans Builder/ What to build :
- Plage de paramètres (périodes)
- Période d'attente
- Paramétrage des Stop Loss et des objectifs de profit
- Définir le nombre maximum de règles en cas d'entrée et de sortie
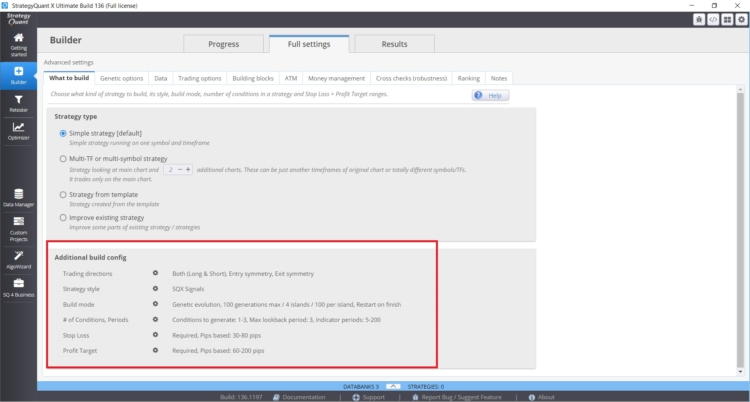
Dans ce cas, plus les valeurs et les intervalles spécifiés sont importants, plus le risque de biais d'exploration de données est élevé. Une bonne pratique consiste à utiliser un maximum de deux règles d'entrée, pour la période de rebouclage, je m'en tiendrais à une valeur maximale de 3. Je vois souvent des stratégies de clients avec 6 conditions et des périodes de rebouclage de 25. Ces combinaisons présentent un risque réel de biais d'exploration de données.
Si vous souhaitez définir des périodes de rétrospection spécifiques pour des blocs spécifiques lorsque cela s'avère utile (clôture quotidienne, etc.), vous pouvez les définir directement pour une règle spécifique, comme vous pouvez le voir dans la figure ci-dessous :
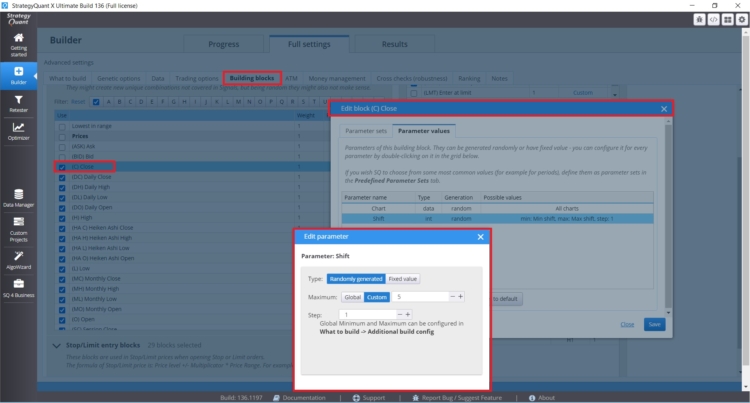
Vous pouvez également contrôler directement les types de blocs de construction, la quantité et les paramètres dans l'onglet Builder - avec Entry Indies/Rules.
Nombre d'indicateurs, de conditions et de blocs de comparaison :
- Nombre de blocs d'entrée possibles
- Nombre de blocs de sortie possibles
- Dans le cas des ordres stop/limite, le nombre d'indicateurs stop/limite est important.
- Types de sorties et d'entrées et leurs réglages.
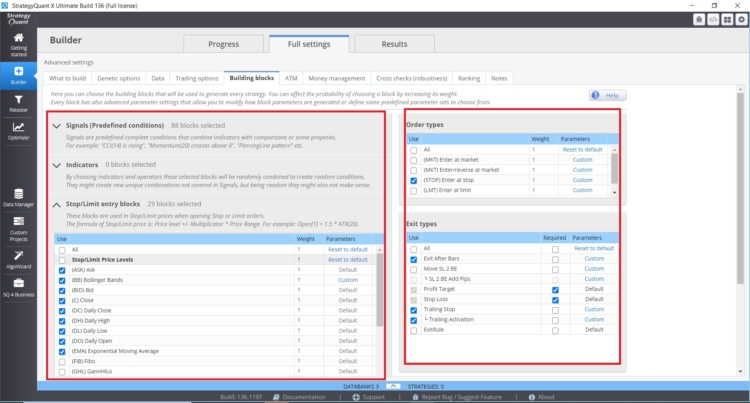
Plus nous introduisons d'options dans le moteur génétique de StrategyQuant X, plus le biais d'exploration des données peut être important.
-
Le nombre d'observations utilisées pour calculer la statistique de performance :
[11]Plus le nombre d'observations est élevé, plus le biais d'exploration des données est faible.
Implications du nombre d'observations dans le développement de la stratégie dans StrategyQuant X :
En général, plus l'échantillon de données est important (nombre de transactions dans l'échantillon), plus la puissance statistique des résultats est élevée.
Pour ce faire, il faut
- Données hors échantillon plus importantes = taille de l'échantillon plus grande
- Plus de marchés testés = taille de l'échantillon plus importante
- Plus de périodes testées = taille de l'échantillon plus importante
De même, du point de vue des statistiques d'interférence, les indicateurs de stratégie identifiés ont une valeur prédictive plus élevée lorsque l'échantillon est suffisamment grand. De même, les statistiques de stratégie identifiées ont plus de poids lorsque la taille de l'échantillon identifié est plus importante. Il convient de souligner qu'il n'est pas nécessaire de prendre en compte les résultats en échantillon si la performance hors échantillon de la stratégie est plus importante. Toutefois, cette performance est également affectée par les biais d'exploration de données associés à la procédure de comparaison multiple. Dans la pratique, cela peut signifier que la performance réelle est très probablement inférieure à la performance du backtest hors échantillon.
Ce point est considéré par Aronson comme le plus important de tous les facteurs. Il affirme que plus l'échantillon de données obtenu est important, moins l'impact négatif des autres facteurs est important. Lors de l'optimisation d'une stratégie existante, il convient de prêter attention aux plages de paramètres et au nombre d'étapes. En général, plus il y a d'options, plus les chances de succès sont grandes.
Comment définir la plage de backtest et la période hors échantillon dans StrategyQuant X ?
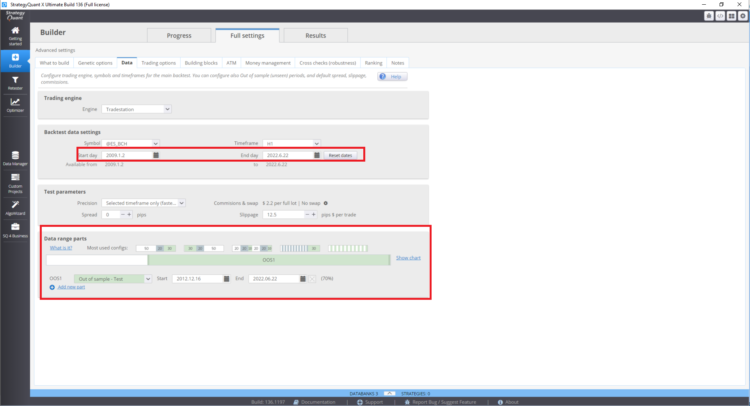
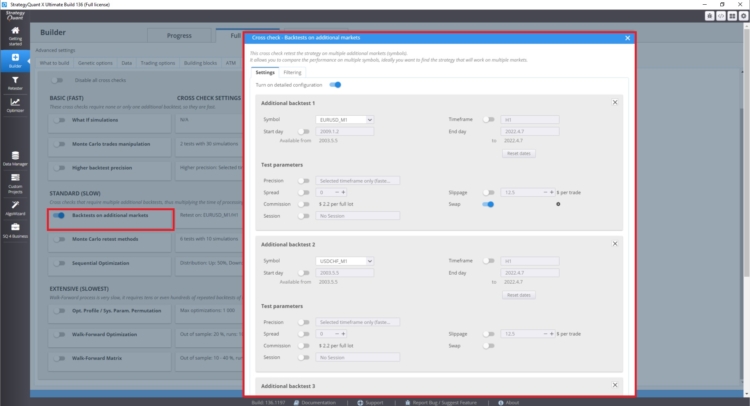
Comment mettre en place des tests multi-marchés ?
Dans la section de vérification croisée sous Backtest on additional markets, vous pouvez définir des backtests sur des marchés supplémentaires.
Où définir la fonction d'aptitude et le classement vrai dans StrategyQuant X
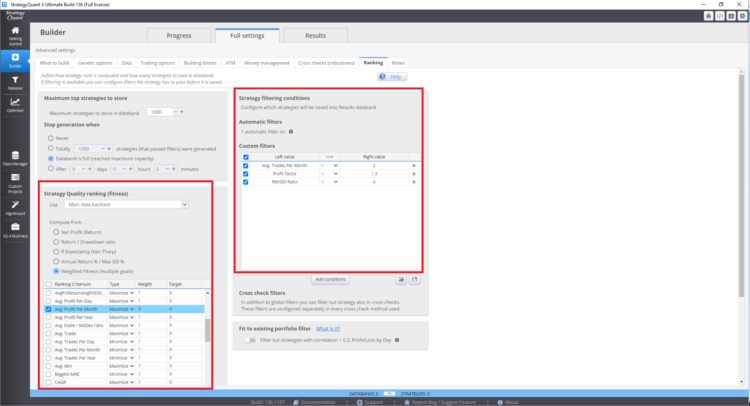
Ces paramètres peuvent affecter les stratégies résultantes dans la banque de données.
-
Corrélation entre les rendements des règles
[12]Il s'agit du degré de corrélation entre les historiques de performance des règles testées. Moins ils sont corrélés, plus le biais d'exploration des données est important.
Plus la corrélation entre les règles testées est forte, plus l'ampleur du biais sera faible. Inversement, plus la corrélation est faible (c'est-à-dire plus le degré d'indépendance statistique est élevé) entre les règles renvoyées, plus le biais d'exploration des données sera important. Cela est logique car une corrélation accrue entre les règles a pour conséquence de réduire le nombre effectif de règles soumises à un test rétrospectif.
Ce point est difficile à appréhender. Il repose sur la connaissance du premier point. Le nombre de stratégies corrélées dans StrategyQuantX peut être affecté par le type de blocs de construction utilisés dans la construction des stratégies, mais aussi par le paramétrage de la recherche génétique de stratégies. Par exemple, si vous ne choisissez que des moyennes mobiles comme éléments de base, il est plus probable que les stratégies soient davantage corrélées entre elles.
Si le nombre de blocs de construction est très faible, vous ne réaliserez pas le potentiel de l'exploration de données ; au contraire, si le nombre de blocs de construction est très élevé, vous risquez d'avoir un biais important dans l'exploration de données. Ces facteurs peuvent également être éliminés par un nombre élevé de transactions ou par des tests multi-marchés.
Vous pouvez gérer ces paramètres dans Constructeur/ options génétiques.
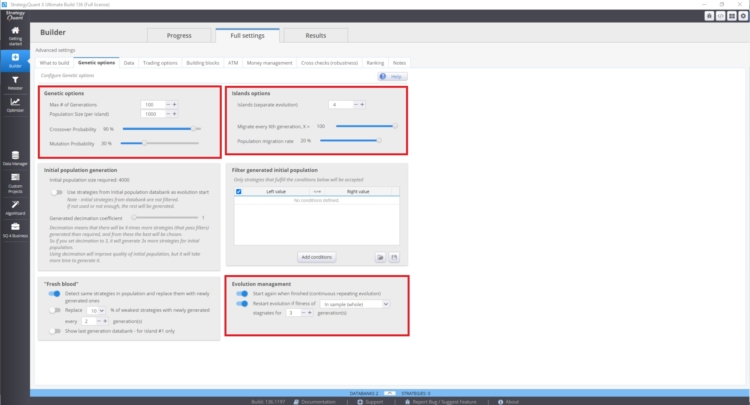
La vitesse de convergence de la courbe d'aptitude et la variabilité des stratégies dépendent :
- Valeur plus élevée de la probabilité de croisement
- Valeur inférieure de la probabilité de mutation
L'évolution des îles peut également avoir un impact majeur. Elle permet la migration des stratégies entre les îles. La gestion de l'évolution peut également jouer un rôle important. En particulier, si nous relançons l'évolution génétique avec un trop grand nombre de générations, nous risquons de nous retrouver avec des stratégies plus corrélées dans la banque de données. Il se peut que la banque de données contienne davantage de stratégies corrélées.
Ces paramètres peuvent être contradictoires et leur utilisation dépend du cas par cas. Ce problème n'est pas facile à comprendre, car l'état de votre base de données dépend de nombreux facteurs.
-
Présence de rendements aberrants positifs
[13]Il s'agit de la présence de rendements très importants dans l'historique de performance d'une règle, par exemple un rendement positif très important un jour donné. Dans ce cas, le biais d'exploration des données tend à être plus important, bien que cet effet soit réduit lorsque le nombre de valeurs aberrantes positives est faible par rapport au nombre total d'observations utilisées pour calculer la statistique de performance. En d'autres termes, un plus grand nombre d'observations dilue l'effet de biais des valeurs aberrantes positives.
Si vous avez une stratégie dont les performances sont affectées par un petit nombre de transactions, vous devez faire attention. Dans StrategyQuant X, il y a des contrôles croisés d'hypothèses qui vous aideront à gérer de telles situations.
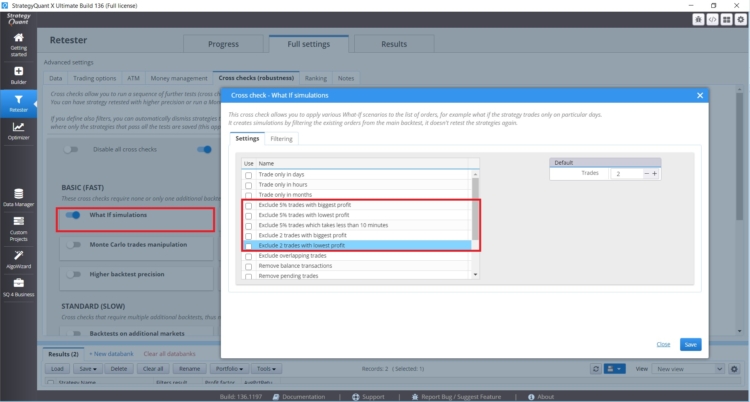
Ces vérifications croisées vous permettent de tester les performances de la stratégie sans les transactions les plus rentables ou les plus rentables. Si les résultats de la stratégie sont déraisonnablement différents, vous devez être prudent.
-
Variation des rendements attendus entre les règles
[14]Il s'agit de la variation du mérite réel (rendement attendu) parmi les règles testées a posteriori. Plus la variation est faible, plus le biais d'exploration des données est important. En d'autres termes, lorsque l'ensemble des règles testées a un pouvoir prédictif similaire, le biais d'exploration de données sera plus important.
Ce phénomène peut être mesuré en analysant la variabilité des résultats dans la base de données. Selon Aronson, plus la variabilité des mesures de performance de la stratégie dans la banque de données est importante, plus le risque de biais lié à l'exploration de données est élevé. Pour analyser les résultats de l'ensemble de la banque de données, vous pouvez utiliser une analyse personnalisée ou exporter la base de données et l'analyser en externe dans Excel ou Python.
Il convient également de mentionner les outils proposés pour traiter les biais liés à l'exploration de données.
- Tests hors échantillon
- Utilisation de techniques de randomisation
- Test de permutation de Monte Carlo
- La réalité des Blancs
- Pénaliser la stratégie métrique
A partir de là, nous pouvons directement influencer la taille de l'échantillon et nous avons également des tests de Monte Carlo disponibles directement dans StrategyQuant X.
Conclusion
De mon point de vue, le plus simple est de se concentrer sur les points suivants.
- Le plus grand nombre possible de transactions hors échantillon.
- Tester plusieurs marchés/calendriers
- Ne pas utiliser toutes les méthodes possibles en même temps
- Définir des blocs de construction en fonction du type de stratégies que je souhaite trouver
Personnellement, j'ai lu ce livre trois fois à différents stades de mon développement et il m'a toujours fait avancer. Il m'a confirmé que l'adoption d'une position critique à l'égard des différents paradigmes dans le domaine de la négociation et des méthodes quantitatives est une bonne méthode, même si elle est parfois difficile. Vous trouverez également de très bonnes informations sur notre blog dans des articles consacrés à des entretiens avec des négociants ou sur le site web https://bettersystemtrader.com/.

Notes de bas de page
[1] Site web de l'auteur, https://www.evidencebasedta.com/
[2] Aronson, D. R. (2021). Dans L'analyse technique fondée sur des données probantes : L'application de la méthode scientifique et de l'inférence statistique aux signaux de trading (pp. 6-6). essai, John Wiley & Sons.
[3] https://www.cuemath.com/data/inferential-statistics/
[4]Aronson, D. R. (2021). Dans L'analyse technique fondée sur des données probantes : L'application de la méthode scientifique et de l'inférence statistique aux signaux de trading (pp. 165-165). essai, John Wiley & Sons.
[5] Aronson, D. R. (2021). Dans L'analyse technique fondée sur des données probantes : L'application de la méthode scientifique et de l'inférence statistique aux signaux de trading (pp. 264-264). essai, John Wiley & Sons.
[6] Aronson, D. R. (2021). Dans L'analyse technique fondée sur des données probantes : L'application de la méthode scientifique et de l'inférence statistique aux signaux de trading (pp. 268-268). essai, John Wiley & Sons.
[7] Aronson, D. R. (2021). Dans L'analyse technique fondée sur des données probantes : L'application de la méthode scientifique et de l'inférence statistique aux signaux de trading (pp. 256-256). essai, John Wiley & Sons.
[8] Aronson, D. R. (2021). Dans L'analyse technique fondée sur des données probantes : L'application de la méthode scientifique et de l'inférence statistique aux signaux de trading (pp. 280-280). essai, John Wiley & Sons.
[9] Source : https://en.wikipedia.org/wiki/Multiple_comparisons_problem
[10] Aronson, D. R. (2021). Dans L'analyse technique fondée sur des données probantes : L'application de la méthode scientifique et de l'inférence statistique aux signaux de trading (pp. 289-289). essai, John Wiley & Sons.
[11] Aronson, D. R. (2021). Dans L'analyse technique fondée sur des données probantes : L'application de la méthode scientifique et de l'inférence statistique aux signaux de trading (pp. 289-289). essai, John Wiley & Sons.
[12] Aronson, D. R. (2021). Dans L'analyse technique fondée sur des données probantes : L'application de la méthode scientifique et de l'inférence statistique aux signaux de trading (pp. 289-289). essai, John Wiley & Sons.
[13] Aronson, D. R. (2021). Dans L'analyse technique fondée sur des données probantes : L'application de la méthode scientifique et de l'inférence statistique aux signaux de trading (pp. 289-289). essai, John Wiley & Sons.
[14] Aronson, D. R. (2021). Dans L'analyse technique fondée sur des données probantes : L'application de la méthode scientifique et de l'inférence statistique aux signaux de trading (pp. 289-289). essai, John Wiley & Sons.

 Ellie Souckova
Ellie Souckova


Bonjour, merci pour votre travail et vos informations. Pourriez-vous nous expliquer en quoi consiste exactement votre stratégie de pénalisation ?
Excellente analyse du travail d'Aronson en ce qui concerne StratQuant. Ce qui n'a pas été explicitement expliqué, c'est le concept de "degrés de liberté" tel qu'il est expliqué dans le livre de Robert Pardo, "Design, Testing, and Opimization of Trading Systems" (1992) et dans sa deuxième édition (2008). Extrait de la première édition : "Placer trop de restrictions sur les données de prix est la première cause de surajustement", p. 138.
Bon travail.