In meinem heutigen Blogbeitrag werde ich versuchen, einige wichtige Ideen aus dem Buch Evidence Based Technical Analysis von David Aronson zusammenzufassen. Das Buch wurde im Jahr 2006 veröffentlicht und wurde ziemlich schnell populär.
Die evidenzbasierte technische Analyse befasst sich thematisch mit der Frage der statistischen Analyse im Zusammenhang mit der Strategieentwicklung und mit der Frage des Data Mining, die den Anwendern Sorgen bereitet. StrategyQuant x ist de facto ein hochentwickeltes Data-Mining-Tool, das so eingesetzt und eingerichtet werden muss, dass das Risiko verringert wird, dass die Strategieperformance tatsächlich ein Zufallsprodukt ist.
Der erste Teil befasst sich mit philosophischen Fragen der wissenschaftlichen Erkenntnis. Er erörtert die technische Analyse und die Analyse als Taktik aus der Perspektive der Philosophie, der Methodik und der Logik und konzentriert sich insgesamt mehr auf theoretische und philosophische Fragen und ihre Auswirkungen auf die Praxis.
Der zweite Teil befasst sich mit dem Einsatz und den Argumenten für den Einsatz strenger statistischer Methoden, insbesondere der Interferenzstatistik, bei der Analyse der Leistung einer algorithmischen Strategie. Der dritte Teil befasst sich mit dem, was uns als SQX-Anwender am meisten beunruhigen könnte - Data-Mining-Verzerrungen im Zusammenhang mit Mehrfachvergleichsmethoden. Der vierte Teil befasst sich mit der Verwendung verschiedener Methoden im Data Mining, einschließlich der Verwendung von Algorithmen bei der Strategiesuche, der Verwendung von Bestätigungsmethoden im Data Mining usw.
Dieser Blog-Beitrag zielt darauf ab, die grundlegenden Konzepte, mit denen David Aronson arbeitet, herauszuarbeiten und sie auf das Thema der Entwicklung von StrategyQuant X anzuwenden. Ich habe mich auf die Teile konzentriert, die SQX-Benutzer am meisten betreffen, und dabei die häufigsten Fehler berücksichtigt, die Neulinge bei der Einrichtung des Programms machen.
Ich zitiere zunächst die kurze BIO von David Aronson:
[1]"David Aronson, Autor von "Evidence-Based Technical Analysis" (John Wiley & Son's 2006) ist außerordentlicher Professor für Finanzen an der Zicklin School of Business, wo er seit 2002 einen Graduiertenkurs in technischer Analyse und Data Mining unterrichtet.
Im Jahr 1977 verließ Aronson Merrill Lynch, um sich unabhängig mit dem aufkommenden Bereich der Managed-Futures-Strategien zu befassen. 1980 gründete er die AdvoCom Corporation, die schon früh die Methoden der modernen Portfoliotheorie und computergestützte Leistungsdatenbanken für die Erstellung von Futures-Portfolios und -Fonds mit mehreren Beratern einsetzte. Ein repräsentatives Portfolio, das 1984 aufgelegt wurde, hat eine jährliche Rendite von 23,7% erzielt. Im Jahr 1990 beriet AdvoCom die Tudor Investment Corporation bei ihrem öffentlichen Multi-Advisor-Fonds.
In den späten siebziger Jahren erkannte Aronson bei der Erforschung computergestützter Strategien für Managed Futures das Potenzial der Anwendung künstlicher Intelligenz bei der Entdeckung von Vorhersagemustern in Finanzmarktdaten. Diese Praxis, die sich jetzt an der Wall Street durchsetzt, wird als Data Mining bezeichnet. 1982 gründete Aronson die Raden Research Group, die schon früh Data Mining und nichtlineare Prognosemodelle für die Entwicklung systematischer Handelsmethoden einsetzte. Aronsons Innovation war die Anwendung von Data Mining zur Verbesserung traditioneller computergestützter Handelsstrategien. Dieser Ansatz wurde zum ersten Mal in Aronsons Artikel "Pattern Recognition Signal Filters" im Market Technican's Journal - Frühjahr 1991 beschrieben. Die Raden Research Group Inc. führte im Auftrag verschiedener Handelsunternehmen wie Tudor Investment Corporation, Manufacturers Hanover Bank, Transworld Oil, Quantlabs und mehrerer großer Einzelhändler Forschungsarbeiten zur Vorhersagemodellierung und Filterentwicklung durch."
Das Buch beginnt mit einer Definition der Grundbegriffe der technischen Analyse und versucht, das gesamte Thema aus der Sicht der Logik zu definieren. Es erörtert philosophische, methodische, statistische und psychologische Fragen bei der Analyse der Finanzmärkte und betont die Bedeutung des wissenschaftlichen Denkens, Urteilens und Argumentierens.
Aronson arbeitet mit zwei Definitionen der technischen Analyse
- Subjektive technische Analyse (TA)
- Objektive technische Analyse (TA)
Subjektive TA, so Aronson, verwendet keine wiederholbaren wissenschaftlichen Methoden und Verfahren. Sie basiert auf den persönlichen Interpretationen der Analysten und ist aus historischer Sicht durch Backtesting nur schwer zu beweisen. Im Gegensatz dazu ist die objektive TA basiert auf der Anwendung von Backtesting-Methoden und der Verwendung objektiver statistischer Analysen der Backtesting-Ergebnisse, so Aronson.
Die Anwendung wissenschaftlicher Methoden in der technischen/quantitativen Analyse ist das Grundthema des gesamten Buches.
[2] "Objektive TA kann auch zu falschen Überzeugungen führen, aber sie entstehen anders. Sie sind auf fehlerhafte Schlussfolgerungen aus objektiven Beweisen zurückzuführen. Die bloße Tatsache, dass sich eine objektive Methode in einem Backtest bewährt hat, ist kein ausreichender Grund für die Schlussfolgerung, dass sie sich bewährt hat. Vergangene Leistungen können uns täuschen. Erfolg in der Vergangenheit ist eine notwendige, aber nicht hinreichende Bedingung für die Schlussfolgerung, dass eine Methode Vorhersagekraft besitzt und daher wahrscheinlich auch in der Zukunft profitabel sein wird. Günstige Ergebnisse in der Vergangenheit können durch Glück oder durch eine Verzerrung nach oben entstehen, die durch eine Form des Backtestings, das so genannte Data Mining, erzeugt wird. Die Frage, wann Backtesting-Gewinne auf eine gute Methode und nicht auf Glück zurückzuführen sind, kann nur durch strenge statistische Schlussfolgerungen beantwortet werden."
Aronson kritisiert die subjektiven TA-Methoden, betont aber auch, dass selbst bei der Anwendung objektiver TA Fehler gemacht werden können.
In diesem Teil war ich sehr an dem Teil über die verschiedenen Formen von Fehlern interessiert, die bei der Lösung von analytischen Problemen üblich sind oder auftreten. Zu den Analysemethoden gehören die sogenannten Verzerrungen, die beim Verstehen von Dingen auftreten
- Voreingenommenheit
- Optimismus-Voreingenommenheit
- Bestätigungsvoreingenommenheit
- Voreingenommenheit bei der Auswahl
- Illusorische Korrelationen
- Optimismus-Voreingenommenheit
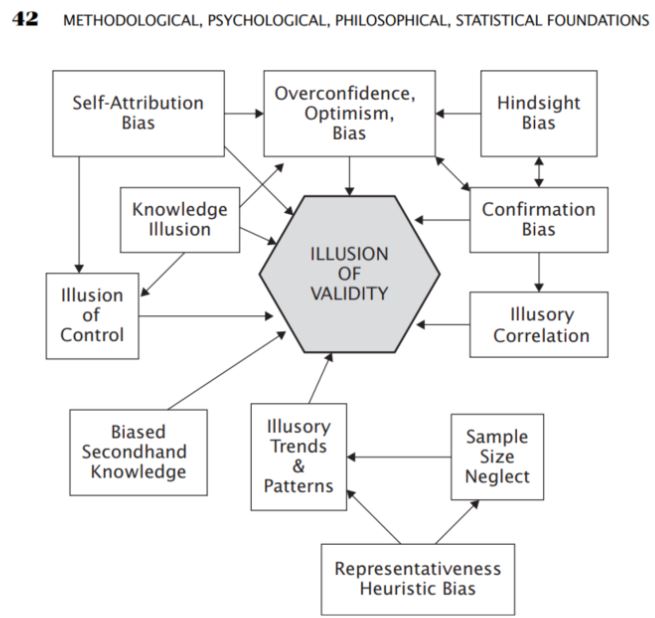
Quelle: Aronson, D. R. (2021). In Evidenzbasierte technische Analyse: Anwendung der wissenschaftlichen Methode und statistischer Schlussfolgerungen auf Handelssignale (S. 42-42). essay, John Wiley & Sons.
Es ist die subjektive TA-Analyse, die oft auf den von Aronson beschriebenen Verzerrungen beruhen kann, aber er weist darauf hin, dass auch bei objektiver - statistischer - TA Verzerrungen oft unbewusst auftreten. Daher schlägt er die Verwendung der so genannten objektiven TA in Form der Anwendung wissenschaftlicher Methoden bei der Analyse vor.
Aronson fasst die Schritte der Hypothesenformulierung in der Interferenzanalyse zusammen - deduktive Methode
- Beobachtung
- Hypothese
- Vorhersage
- Überprüfung
- Schlussfolgerung
In den folgenden Kapiteln erläutert Aronson die Bedeutung einer strengen statistischen Analyse bei der Bewertung von Strategien.
[3]"Inferenzstatistik hilft dabei, ein gutes Verständnis der Populationsdaten zu entwickeln, indem die daraus gewonnenen Stichproben analysiert werden. Sie hilft bei der Erstellung von Verallgemeinerungen über die Grundgesamtheit, indem sie verschiedene analytische Tests und Instrumente einsetzt. Zur Auswahl von Zufallsstichproben, die die Grundgesamtheit genau repräsentieren, werden zahlreiche Stichprobenverfahren eingesetzt. Einige der wichtigsten Methoden sind einfache Zufallsstichproben, geschichtete Stichproben, Cluster-Stichproben und systematische Stichprobenverfahren."
Aronson definiert sie im Zusammenhang mit dem Einsatz der Technischen Analyse:
[4]"Die Feststellung, welche TA-Methoden eine echte Vorhersagekraft haben, ist äußerst unsicher. Selbst die stärksten Regeln zeigen von einem Datensatz zum nächsten sehr unterschiedliche Leistungen. Daher ist die statistische Analyse die einzige praktische Möglichkeit, um nützliche von weniger nützlichen Methoden zu unterscheiden. Unabhängig davon, ob die Praktiker dies anerkennen oder nicht, ist der Kern der TEA die statistische Inferenz. Es wird versucht, aus historischen Daten Verallgemeinerungen in Form von Mustern, Regeln usw. zu entdecken und diese dann auf die Zukunft zu extrapolieren. Die Extrapolation ist von Natur aus unsicher. Ungewissheit ist unangenehm."
Im Kontext der Strategieentwicklung in StrategyQuant kann X als eine Stichprobe aus der Grundgesamtheit betrachtet werden.
- Liste der Gewerke und ihrer Metriken
- Liste der Strategien in der Datenbank und ihre Strategiemetriken
Ich möchte die Themen Interferenzstatistik, Hypothesentests und deskriptive Statistik nicht marginalisieren, aber ihr Umfang und ihre Auswirkungen gehen weit über den Rahmen dieses Artikels hinaus, daher
Ich empfehle Ihnen, diese Ressourcen durchzuarbeiten:
Data Mining
[5]Data Mining ist die Extraktion von Wissen in Form von Mustern, Regeln, Modellen, Funktionen usw. aus großen Datenbanken.
Für uns als Nutzer von StrategyQuant X ist es wahrscheinlich, dass wir bei unserer Suche nach profitablen Strategien eine Form von Data Mining einsetzen
Mit StrategyQuant X setzen wir Data Mining in der Regel ein, wenn wir nach folgenden Punkten suchen
- Strategiesuche ( Builder )
- Strategie-Optimierung ( Optimierung )
Aronson weist auf die Unterschiede zwischen klassischer Strategieentwicklung und Data Mining hin:
- Wir betrachten die klassische Methode als diejenige, bei der ein Entwickler eine Strategie von Grund auf ohne Einsatz von Data-Mining-Methoden. Im Zusammenhang mit StrategyQuant X könnten wir an die manuelle Strategieerstellung im Algowizard denken, wo wir Strategien nach unserer Logik erstellen können.
- Beim Einsatz von Data Mining, wir testen eine große Anzahl von Regeln um die Strategie mit der höchsten beobachteten Leistung und der höchsten Wahrscheinlichkeit einer zukünftigen Leistung zu finden.
Aronson argumentiert für den Einsatz von Data Mining wie folgt:
-
[6]Erstens: Es funktioniert. Die später in diesem Kapitel vorgestellten Experimente werden zeigen, dass unter ziemlich allgemeinen Bedingungen die Wahrscheinlichkeit, eine gute Regel zu finden, umso größer ist, je mehr Regeln getestet werden.
-
Zweitens begünstigt die technologische Entwicklung das Data Mining. Die Kosteneffizienz von Personalcomputern, die Verfügbarkeit von leistungsfähiger Backtesting- und Data-Mining-Software und die Verfügbarkeit historischer Datenbanken machen Data Mining nun auch für Privatpersonen praktikabel. Noch vor einem Jahrzehnt war Data Mining aufgrund der Kosten auf institutionelle Anleger beschränkt.
-
Drittens fehlt der TA in ihrem derzeitigen Entwicklungsstadium die theoretische Grundlage, die einen traditionelleren wissenschaftlichen Ansatz zum Wissenserwerb ermöglichen würde
Voreingenommenheit beim Data Mining
Aronson argumentiert, dass Verzerrungen beim Data Mining ein möglicher Hauptgrund für das Scheitern von Strategien beim Out-of-Sample- oder Realhandel sein könnten.
[7]"Data-Mining-Verzerrung: die erwartete Differenz zwischen der beobachteten Leistung der besten Regel und ihrer erwarteten Leistung. Die erwartete Differenz bezieht sich auf eine langfristige durchschnittliche Differenz, die sich aus zahlreichen Experimenten ergibt, die die Differenz zwischen der beobachteten Rendite der besten Regel und der erwarteten Rendite der besten Regel messen."
Dabei werden die beiden Hauptkomponenten der beobachteten Leistung (Strategieleistung) wie folgt berücksichtigt.
- Vorhersehbarkeit der Strategie
- Zufälligkeit - Glück
[8]"Jetzt kommen wir zu einem wichtigen Prinzip. Je größer der Anteil des Zufalls (Glück) im Verhältnis zum Verdienst an der beobachteten Performance (Backtest-Ergebnisse) ist, desto größer ist die Verzerrung des Data-Mining. Der Grund dafür ist folgender: Je größer der Anteil des Glücks im Verhältnis zum Verdienst ist, desto größer ist die Wahrscheinlichkeit, dass eine der vielen Kandidatenregeln (Strategien) eine außerordentlich glückliche Performance aufweist. Dies ist der Kandidat, der vom Data Miner ausgewählt wird. In Situationen, in denen die beobachtete Leistung ausschließlich oder primär auf die tatsächliche Leistung eines Kandidaten zurückzuführen ist, ist die Verzerrung durch das Data Mining jedoch nicht vorhanden oder sehr gering. In diesen Fällen ist die bisherige Leistung eines Kandidaten ein zuverlässiger Prädiktor für die künftige Leistung, und der Data Miner wird den Trichter nur selten mit Narrengold füllen. Da die Finanzmärkte extrem schwer vorhersehbar sind, ist der größte Teil der beobachteten Leistung einer Regel eher auf Zufälligkeiten als auf ihre Vorhersagekraft zurückzuführen. "
Im Zusammenhang mit StrategyQuant X können wir sagen, dass das Element des Zufalls mit der wohlwollenden Haltung von StrategyQuant X verbunden ist. Ienn wir bei der Suche nach Strategien zu viele Kombinationen wählen, kann es sein, dass StrategyQuant X eine findet, die einen positiven Backtest hat, aber in der Realität der Strategie nicht funktioniert. Unten am Ende des Blogbeitrags werden die Faktoren, die diese Zufälligkeit beeinflussen, mit Tipps im StrategyQuant X Setup zusammengefasst.
Viel Aufmerksamkeit wird auch dem Mehrfachvergleichsverfahren (MCP ) gewidmet. Wikipedia definiert die Mehrfachvergleichsverfahren als:
[9]"Mehrfache Vergleiche entstehen, wenn eine statistische Analyse mehrere gleichzeitige statistische Tests umfasst, von denen jeder das Potenzial hat, eine "Entdeckung" zu machen. Ein angegebenes Konfidenzniveau gilt im Allgemeinen nur für jeden einzeln betrachteten Test, aber oft ist es wünschenswert, ein Konfidenzniveau für die gesamte Familie der gleichzeitigen Tests zu haben."
Im Kontext von StrategyQuant X können wir das Problem der multiplen Vergleiche überall dort anwenden, wo wir nach einer großen Anzahl von Indikatoren/Bedingungen/Einstellungen einer bestimmten Strategie in einem großen Spektrum suchen. Mit den Methoden der multiplen Vergleiche können wir leicht feststellen, dass die gefundene Lösung, in unserem Fall die Strategie und ihre Out-of-Sample-Performance, das Ergebnis des Zufalls und einer großen Anzahl von getesteten Kombinationen ist. Je mehr Regeln und je mehr Variabilität im SQX-Setup verwendet werden, desto höher ist die Wahrscheinlichkeit, dass die Performance der Strategie im OS ein Zufallsprodukt ist, und desto höher ist daher die Wahrscheinlichkeit, dass die Strategie im realen Handel scheitern wird.
Aronson beweist die im folgenden Abschnitt dargestellten Schlussfolgerungen, indem er die datengesteuerten Handelsregeln für den S&P 500 Index über den Zeitraum von 1328 bis 2003 experimentell durchführt. Die genaue Vorgehensweise finden Sie auf Seite 292. Ein ähnliches Experiment kann in StrategyQuant X für jeden beliebigen Markt leicht wiederholt werden.
5 Faktoren, die den Grad der Verzerrung beim Data Mining beeinflussen
-
Anzahl der rückgeprüften Regeln:
[10]"Dies bezieht sich auf die Gesamtzahl der Regeln, die während des Data-Mining-Prozesses auf dem Weg zur Ermittlung der leistungsstärksten Regel getestet wurden. Je größer die Anzahl der getesteten Regeln ist, desto größer ist die Verzerrung des Data-Mining-Prozesses.
Auswirkungen Anzahl der Regeln, die bei der Entwicklung von Strategien in StrategyQuant rückgeprüft wurden X
Die Anzahl der Regeln, die bei der Strategiesuche verwendet werden, kann in StrategyQuant X durch die folgenden Einstellungen im Builder/ What to build beeinflusst werden:
- Parameterbereich ( Perioden)
- Rückblickzeitraum
- Einstellungen von Stop Losses und Gewinnzielen
- Legen Sie die maximale Anzahl von Regeln für die Ein- und Ausreise fest.
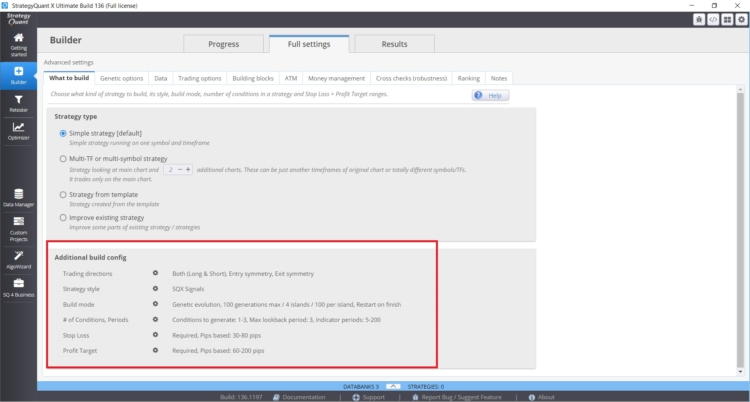
In diesem Fall ist das Risiko einer Verzerrung durch Data Mining umso größer, je größer die Werte und Bereiche sind, die Sie angeben.. Eine gute Praxis ist es, maximal zwei Eingaberegeln zu verwenden, für die Loopback-Periode würde ich bei einem Maximalwert von 3 bleiben. Ich sehe oft von Kunden Strategien mit 6 Bedingungen und Lookback-Perioden von 25. Bei diesen Kombinationen besteht ein echtes Risiko von Data-Mining-Verzerrungen.
Wenn Sie bestimmte Rückblickzeiträume für bestimmte Blöcke festlegen möchten, wo dies sinnvoll ist (Tagesabschluss usw.), können Sie diese direkt für eine bestimmte Regel festlegen, wie Sie in der Abbildung unten sehen können:
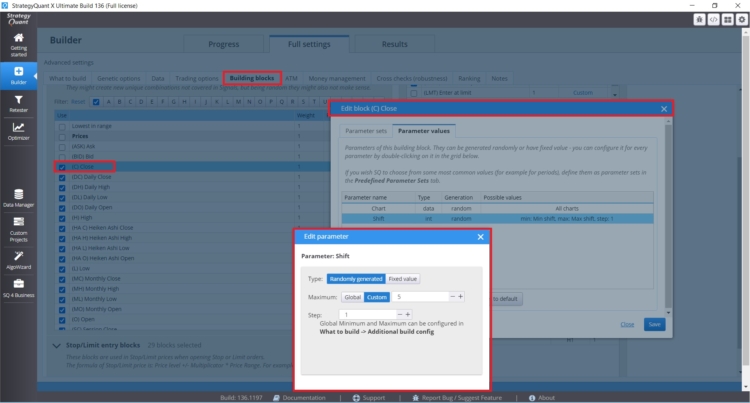
Sie können die Bausteintypen, -mengen und -einstellungen auch direkt im Builder - Tab mit Eintragsindizes/Regeln steuern.
Anzahl der Indikatoren, Bedingungen und Vergleichsblöcke:
- Anzahl der möglichen Eingabeblöcke
- Anzahl der möglichen Ausgangssperren
- Im Falle von Stop/Limit-Aufträgen ist die Anzahl der Indikatoren Stop-Limit wichtig
- Arten von Ausgängen und Eingängen und ihre Einstellungen.
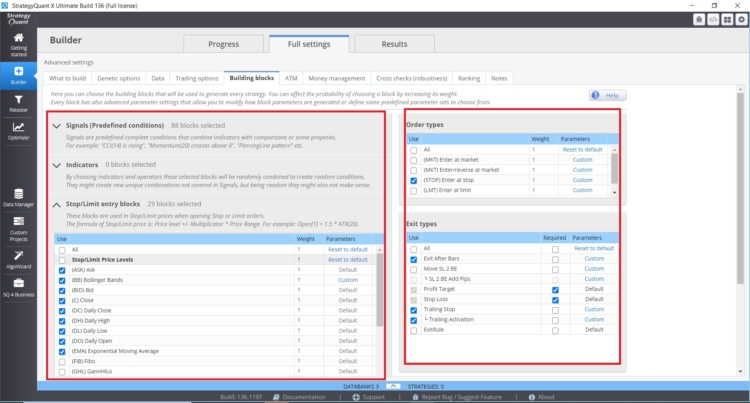
Je mehr Optionen wir in die genetische Engine von StrategyQuant X einbauen, desto größer kann die Verzerrung beim Data Mining sein.
-
Die Anzahl der Beobachtungen, die für die Berechnung der Leistungsstatistik verwendet werden:
[11]Je größer die Anzahl der Beobachtungen ist, desto geringer ist die Verzerrung bei der Datenauswertung.
Auswirkungen der Anzahl der Beobachtungen auf die Strategieentwicklung in StrategyQuant X:
Generell, Je größer die Datenstichprobe ist (Anzahl der Abschlüsse in der Stichprobe), desto höher ist die statistische Aussagekraft der Ergebnisse.
Dies kann erreicht werden durch:
- Größere Daten außerhalb der Stichprobe = größerer Stichprobenumfang
- Mehr getestete Märkte = größerer Stichprobenumfang
- Mehr getestete Zeiträume = größerer Stichprobenumfang
Auch aus Sicht der Interferenzstatistik haben die ermittelten Strategieindikatoren einen höheren Vorhersagewert, wenn die Stichprobe groß genug ist. Ebenso haben die ermittelten Strategiestatistiken mehr Gewicht, wenn die ermittelte Stichprobengröße größer ist. Es ist zu betonen, dass die In-Sample-Ergebnisse nicht berücksichtigt werden müssen, wenn die Out-of-Sample-Leistung der Strategie von größerem Wert ist. Dies wird jedoch auch durch Data-Mining-Verzerrungen im Zusammenhang mit dem Mehrfachvergleichsverfahren beeinflusst. In der Praxis kann dies bedeuten, dass die tatsächliche Performance sehr wahrscheinlich schlechter ist als die Out-of-Sample-Backtest-Performance.
Dieser Punkt wird von Aronson als der wichtigste aller Faktoren angesehen. Er argumentiert, dass die negativen Auswirkungen der anderen Faktoren umso geringer sind, je größer die Stichprobe der erhobenen Daten ist. Achten Sie bei der Optimierung einer bestehenden Strategie auf die Parameterbereiche und die Anzahl der Schritte. Im Allgemeinen gilt: Je mehr Optionen, desto größer die Chance auf Zufall.
Wie man in StrategyQuant X den Backtest-Bereich und den Zeitraum außerhalb der Stichprobe festlegt
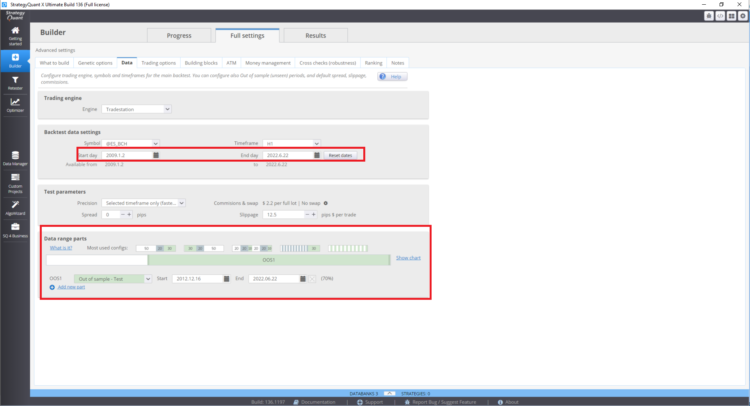
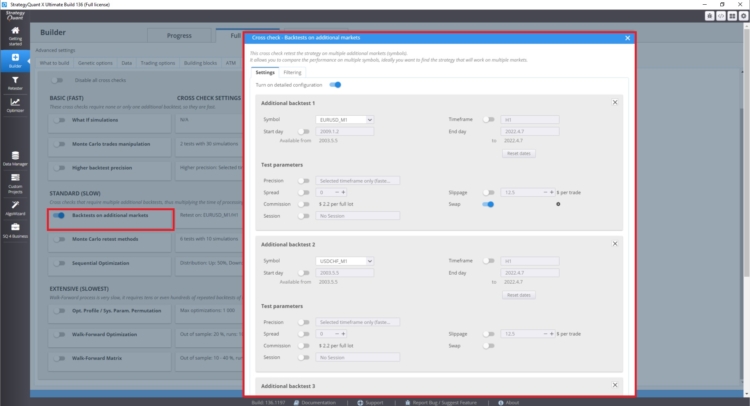
Wie man Multi-Market-Tests einrichtet
Im Abschnitt Cross-Check unter Backtest auf weiteren Märkten können Sie Backtests auf weiteren Märkten einstellen.
Wo werden die Fitnessfunktion und die Rangfolge in StrategyQuant X festgelegt?
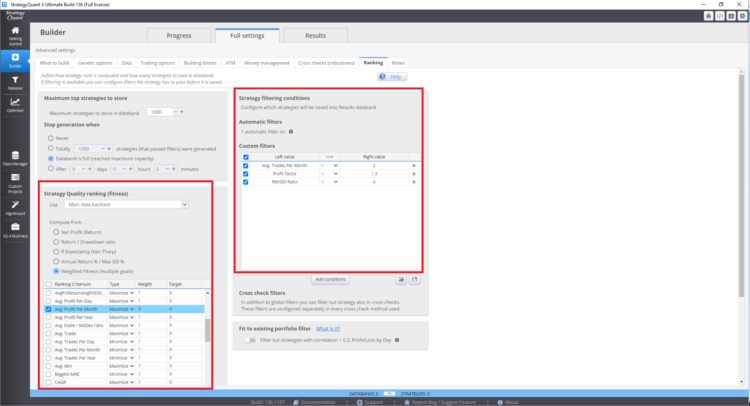
Diese Einstellungen können sich auf die resultierenden Strategien in der Datenbank auswirken.
-
Korrelation zwischen den Regelerträgen
[12]Dies bezieht sich auf den Grad, in dem die Leistungsverläufe der getesteten Regeln miteinander korreliert sind. Je weniger sie miteinander korrelieren, desto größer ist die Verzerrung beim Data-Mining.
Je stärker die Korrelation zwischen den getesteten Regeln ist, desto geringer ist die Verzerrung. Umgekehrt gilt: Je geringer die Korrelation (d. h. je größer der Grad der statistischen Unabhängigkeit) zwischen den zurückgegebenen Regeln ist, desto größer ist die Verzerrung beim Data-Mining. Dies ist sinnvoll, da eine höhere Korrelation zwischen den Regeln dazu führt, dass die effektive Anzahl der Regeln, die zurückgetestet werden, sinkt.
Dieser Punkt ist schwer zu begreifen. Er basiert auf der Kenntnis des ersten Punktes. Die Anzahl der korrelierten Strategien in StrategyQuantX kann durch die Art der in der Strategiekonstruktion verwendeten Bausteine, aber auch durch die Einstellung der genetischen Suche nach Strategien beeinflusst werden. Wenn Sie zum Beispiel nur gleitende Durchschnitte als Bausteine wählen, ist es wahrscheinlicher, dass die Strategien stärker miteinander korrelieren.
Wenn die Anzahl der Bausteine sehr niedrig ist, wird das Potenzial des Data Mining nicht ausgeschöpft; ist die Anzahl der Bausteine hingegen sehr hoch, besteht die Gefahr einer großen Verzerrung des Data Mining. Diese Faktoren können auch durch eine hohe Anzahl von Trades oder durch Multi-Market-Tests eliminiert werden.
Sie können diese Einstellungen verwalten unter Bauherr/ Genetische Optionen.
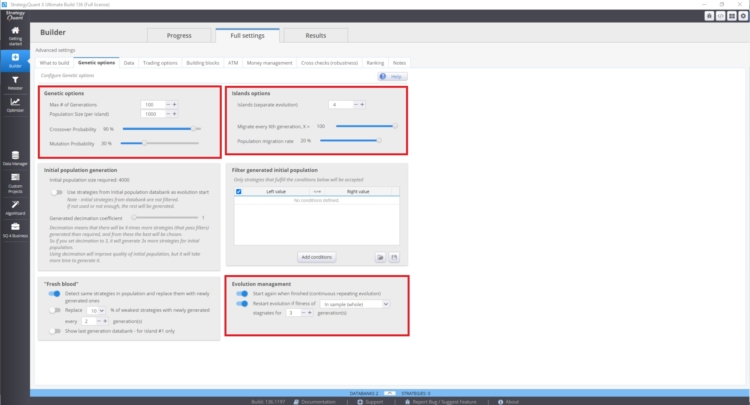
Die Geschwindigkeit der Konvergenz der Fitnesskurve und die Variabilität der Strategien hängen davon ab:
- Höherer Wert der Crossover-Wahrscheinlichkeit
- Unterer Wert der Mutationswahrscheinlichkeit
Auch die Entwicklung von Inseln kann einen großen Einfluss haben. Sie sorgt für die Migration von Strategien zwischen Inseln. Auch das Evolutionsmanagement kann eine wichtige Rolle spielen. Vor allem, wenn wir die genetische Evolution mit zu vielen Generationen neu starten. Dies kann dazu führen, dass man mehr korrelierte Strategien in der Datenbank hat.
Diese Einstellungen können im Widerspruch zueinander stehen, und ihre Verwendung hängt vom jeweiligen Einzelfall ab. Dieses Problem ist nicht einfach zu verstehen, da der Zustand Ihrer Datenbank von vielen Faktoren abhängt.
-
Vorhandensein von positiven Ausreißern
[13]Dies bezieht sich auf das Vorhandensein von sehr großen Erträgen in der Performance-Historie einer Regel, z. B. ein sehr großer positiver Ertrag an einem bestimmten Tag. Wenn solche Ausreißer vorhanden sind, ist die Verzerrung durch das Data-Mining tendenziell größer, obwohl dieser Effekt verringert wird, wenn die Anzahl der positiven Ausreißer im Verhältnis zur Gesamtzahl der Beobachtungen, die zur Berechnung der Leistungsstatistik verwendet werden, gering ist. Mit anderen Worten, mehr Beobachtungen schwächen die verzerrende Wirkung positiver Ausreißer ab.
Wenn Sie eine Strategie haben, deren Leistung von einer kleinen Anzahl von Geschäften beeinflusst wird, sollten Sie darauf achten. In StrategyQuant X gibt es "What-if"-Crosschecks, die Ihnen helfen, mit solchen Situationen umzugehen
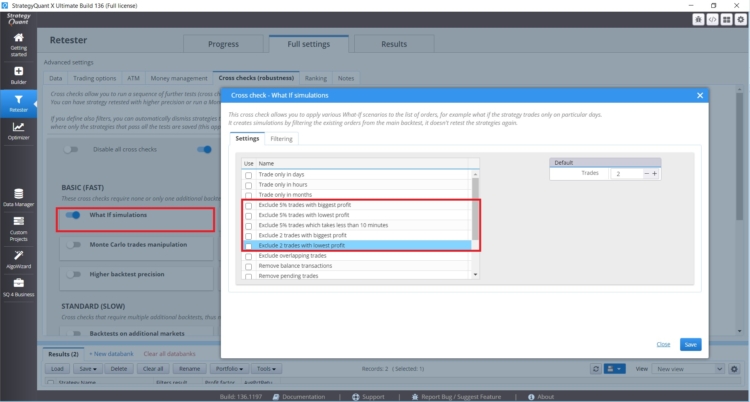
Diese What If Cross Checks ermöglichen es Ihnen, die Leistung der Strategie ohne die profitabelsten oder profitabelsten Trades zu testen. Wenn die Ergebnisse der Strategie unangemessen unterschiedlich sind, müssen Sie vorsichtig sein.
-
Abweichung der erwarteten Rendite zwischen den Regeln
[14]Dies bezieht sich auf die Streuung des tatsächlichen Nutzens (erwartete Rendite) der getesteten Regeln. Je geringer die Variation ist, desto größer ist die Data-Mining-Verzerrung. Mit anderen Worten: Wenn die getesteten Regeln einen ähnlichen Grad an Vorhersagekraft haben, ist die Data-Mining-Verzerrung größer.
Dieses Phänomen kann durch die Analyse der Variabilität der Ergebnisse in der Datenbank gemessen werden. Laut Aronson ist das Risiko einer Verzerrung durch Data Mining umso größer, je größer die Variabilität der strategischen Leistungskennzahlen in der Datenbank ist. Um die Ergebnisse der gesamten Datenbank zu analysieren, können Sie eine benutzerdefinierte Analyse verwenden oder die Datenbank exportieren und sie extern in Excel oder Python analysieren.
Erwähnenswert sind auch die vorgeschlagenen Instrumente für den Umgang mit Data-Mining-Verzerrungen
- Tests außerhalb der Stichprobe
- Einsatz von Randomisierungstechniken
- Monte-Carlo-Permutationstests
- Weißer Realitätscheck
- Benachteiligende Strategie-Metrik
Von hier aus können wir die Stichprobengröße direkt beeinflussen und wir haben auch Monte Carlo Tests direkt in StrategyQuant X verfügbar.
Schlussfolgerung
Aus meiner Sicht ist es am einfachsten, sich auf die folgenden Punkte zu konzentrieren.
- Die größtmögliche Anzahl von Geschäften außerhalb der Stichprobe.
- Prüfung mehrerer Märkte/Zeitrahmen
- Nicht alle möglichen Methoden gleichzeitig anwenden
- Festlegung von Bausteinen entsprechend der Art der Strategien, die ich finden möchte
Ich persönlich habe das Buch dreimal in verschiedenen Stadien meiner Entwicklung gelesen und es hat mich immer weitergebracht. Es hat mich darin bestätigt, dass es ein guter, wenn auch manchmal schwieriger Weg ist, eine kritische Haltung gegenüber verschiedenen Paradigmen im Bereich des Handels und der quantitativen Methoden einzunehmen. Sehr gute Einblicke finden Sie auch in unserem Blog in Artikeln über Interviews mit Händlern oder auf der Website https://bettersystemtrader.com/.

Fußnoten
[1] Website des Autors, https://www.evidencebasedta.com/
[2] Aronson, D. R. (2021). In Evidenzbasierte technische Analyse: Anwendung der wissenschaftlichen Methode und statistischer Schlussfolgerungen auf Handelssignale (S. 6-6). essay, John Wiley & Sons.
[3] https://www.cuemath.com/data/inferential-statistics/
[4]Aronson, D. R. (2021). In Evidenzbasierte technische Analyse: Anwendung der wissenschaftlichen Methode und statistischer Schlussfolgerungen auf Handelssignale (S. 165-165). essay, John Wiley & Sons.
[5] Aronson, D. R. (2021). In Evidenzbasierte technische Analyse: Anwendung der wissenschaftlichen Methode und statistischer Schlussfolgerungen auf Handelssignale (S. 264-264). essay, John Wiley & Sons.
[6] Aronson, D. R. (2021). In Evidenzbasierte technische Analyse: Anwendung der wissenschaftlichen Methode und statistischer Schlussfolgerungen auf Handelssignale (S. 268-268). essay, John Wiley & Sons.
[7] Aronson, D. R. (2021). In Evidenzbasierte technische Analyse: Anwendung der wissenschaftlichen Methode und statistischer Schlussfolgerungen auf Handelssignale (S. 256-256). essay, John Wiley & Sons.
[8] Aronson, D. R. (2021). In Evidenzbasierte technische Analyse: Anwendung der wissenschaftlichen Methode und statistischer Schlussfolgerungen auf Handelssignale (S. 280-280). essay, John Wiley & Sons.
[9] Quelle: https://en.wikipedia.org/wiki/Multiple_comparisons_problem
[10] Aronson, D. R. (2021). In Evidenzbasierte technische Analyse: Anwendung der wissenschaftlichen Methode und statistischer Schlussfolgerungen auf Handelssignale (S. 289-289). essay, John Wiley & Sons.
[11] Aronson, D. R. (2021). In Evidenzbasierte technische Analyse: Anwendung der wissenschaftlichen Methode und statistischer Schlussfolgerungen auf Handelssignale (S. 289-289). essay, John Wiley & Sons.
[12] Aronson, D. R. (2021). In Evidenzbasierte technische Analyse: Anwendung der wissenschaftlichen Methode und statistischer Schlussfolgerungen auf Handelssignale (S. 289-289). essay, John Wiley & Sons.
[13] Aronson, D. R. (2021). In Evidenzbasierte technische Analyse: Anwendung der wissenschaftlichen Methode und statistischer Schlussfolgerungen auf Handelssignale (S. 289-289). essay, John Wiley & Sons.
[14] Aronson, D. R. (2021). In Evidenzbasierte technische Analyse: Anwendung der wissenschaftlichen Methode und statistischer Schlussfolgerungen auf Handelssignale (S. 289-289). essay, John Wiley & Sons.

 Ellie Souckova
Ellie Souckova


Hallo, ich danke Ihnen für alle Ihre harten und informativen könnten Sie erarbeiten, was genau Ihre Bestrafung Strategie Metrik ist
Ausgezeichneter Überblick über die Arbeit von Aronson in Bezug auf StratQuant. Was nicht ausdrücklich erklärt wurde, war das Konzept der "Freiheitsgrade", wie es in Robert Pardos Buch "Design, Testing, and Opimization of Trading Systems" (1992) und seiner zweiten Auflage (2008) erläutert wird. Aus der 1. Auflage: "Die Hauptursache für eine Überanpassung ist, dass den Preisdaten zu viele Einschränkungen auferlegt werden", S. 138.
Gute Arbeit.