Das neue SQ Build 125 führt mehrere Datenbereichsteile ein. Bisher konnten Sie Ihre Verlaufsdaten nur in zwei Teile unterteilen:
- In der Probe - Hier werden die Strategien mit Hilfe der genetischen Evolution weiterentwickelt. Das bedeutet, dass die Strategie in diesem Teil der Daten bewertet wird und ihre Leistungsbewertung (Fitness) aus den Metriken in diesem Teil der Daten berechnet wird. Diese Fitness bestimmt dann, welche Strategien in der Population ausgewählt werden, um gekreuzt und mutiert zu werden, um eine neue Generation zu schaffen. Die besten Strategien haben die höchste Wahrscheinlichkeit, dafür ausgewählt zu werden, und dank dessen sollte die Population als Ganzes mit jeder Generation besser werden.
- Außerhalb der Probe - Dies ist der "unbekannte" Teil der Daten, der nicht Teil der Evolution war. Er wird verwendet, um zu überprüfen, ob die Strategien auch bei "unbekannten" Daten funktionieren.
Die genetische Evolution sieht diesen Teil der Daten nicht.
Der neue Build 125 fügt zwei weitere mögliche Typen hinzu, so dass es insgesamt 4 sind:
- Ausbildung nach Muster (IST) - Dies ist dasselbe wie in der bisherigen Stichprobe. Die genetische Evolution nutzt diesen Teil, um die Fitness zu bestimmen und die Strategien in der Population zu ordnen.
- Validierung von Proben (ISV) - ein neuer Teil in SQ X, der dazu dient, festzustellen, ob die Leistung der Strategie im IST-Teil auch im ISV-Teil gilt.
Beim maschinellen Lernen wird sie verwendet, um festzustellen, ob Modelle, die in der Trainingsmenge (IST) trainiert wurden, auch in der Validierungsmenge gültig sind.
In SQ X kann es verwendet werden, um die genetische Evolution neu zu starten, wenn die Fitness in diesem Teil stagniert.
- Außerhalb der Stichprobe - dies ist dasselbe wie vorher, es stellt einen "unbekannten" Teil der Daten dar, der nicht Teil der Entwicklung war
- Kein Handel - spezieller Teil, der bedeutet, dass die Strategie in diesem Teil nicht handeln wird. Es kann zum Beispiel verwendet werden, um einen Teil in der Mitte der Daten zu überspringen, der eine geringe Volatilität aufweist.
Die allgemeine Empfehlung beim maschinellen Lernen lautet, die Verlaufsdaten in drei gleiche Teile aufzuteilen: IST, ISV und OOS.

Eine andere mögliche Aufteilung wäre 60/20/20, oder der Zeitraum außerhalb der Stichprobe könnte nach vorne verschoben werden.
Mehrere Datenabschnitte
Eine weitere neue Funktion von SQ X B 125 ist, dass Sie die Möglichkeit haben mehrere Validierung in der Probe oder außerhalb der Probe Teile, nicht nur eine, und in beliebiger Reihenfolge.
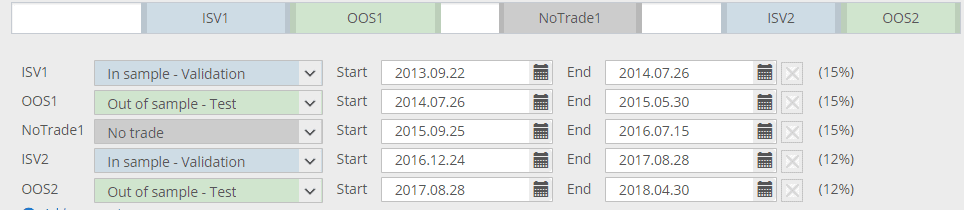
In der obigen Abbildung sind die weißen Teile alle "In Sample Training" - das sind die Daten, auf deren Grundlage die Strategien entwickelt werden.
Blaue (ISV-)Teile sind Daten, anhand derer Strategien überprüft werden, und die Evolution kann neu gestartet werden, wenn sie stagniert.
Der graue (nicht gehandelte) Teil ist derjenige, der ausgelassen wird - die Strategie wird hier nicht gehandelt.
Grüne Teile sind OOS-Teile - sie sind nicht Teil der genetischen Evolution und die Strategien werden anhand unbekannter Daten bewertet.
Bedingungen und Filterung für jeden Abschnitt
Alle Metriken sind jetzt auch unabhängig für jeden dieser Teile berechnet werdenund Sie können sie unter Ihren Bedingungen verwenden.
Sie können zum Beispiel Strategien herausfiltern, bei denen: Der Nettogewinn (OOS1) ist schlechter als 80% des Nettogewinns (OOS2).
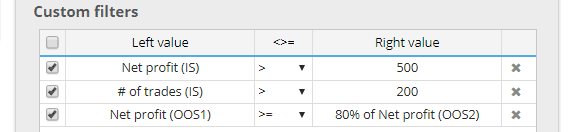
Dies ermöglicht Ihnen eine "strengere" Filterung, bei der die Strategie bei mehreren Teilen der Daten gut funktionieren muss.
 Tomas Vanek
Tomas Vanek

Dankeschön
In diesem Fall umfasst der Reingewinn (IS) IST, ISV1 und ISV2. Liege ich richtig?
Good question. Anybody from the SQ team who want to answer?
Ja, richtig
Ich komme mir sehr dumm vor, wenn ich versuche zu verstehen, was das bedeutet.
Wenn Sie eine spezielle Frage haben, können Sie sie gerne stellen.
Can you explain with more details what’s the difference between ISV and OOS? Maybe is something related to machine learning but I don’t get it
That is a data part in SQ X that is used to determine if strategy performance in IST (training part) holds also in ISV part. In SQ X it can be used to restart genetic evolution when fitness stagnates in this part. So it is kind of semi-OOS used to verify performance before it is verified on OOS