La nouvelle version 125 de SQ introduit plusieurs parties de la plage de données. Jusqu'à présent, vous ne pouviez diviser vos données historiques qu'en deux parties :
- Dans l'échantillon - c'est ici que les stratégies évoluent à l'aide de l'évolution génétique. Cela signifie que la stratégie est évaluée sur cette partie des données et que son score de performance (fitness) est calculé à partir des métriques de cette partie des données. Ce fitness détermine ensuite quelles stratégies de la population sont sélectionnées pour être croisées et mutées afin de créer une nouvelle génération. Les meilleures stratégies ont la plus forte probabilité d'être choisies à cette fin et, grâce à cela, la population dans son ensemble devrait s'améliorer à chaque génération.
- Hors échantillon - il s'agit de la partie "inconnue" des données qui ne faisait pas partie de l'évolution. Elle est utilisée pour vérifier que les stratégies fonctionnent également sur des données "inconnues".
L'évolution génétique ne voit pas cette partie des données.
La nouvelle version 125 ajoute deux autres types possibles, soit 4 au total :
- Formation en échantillon (IST) - c'est la même chose que l'échantillon In que nous avions jusqu'à présent. L'évolution génétique utilise cette partie pour déterminer l'aptitude et classer les stratégies dans la population.
- Validation de l'échantillon (ISV) - une nouvelle partie dans SQ X qui est utilisée pour déterminer si la performance de la stratégie dans la partie IST est également valable dans la partie ISV.
Dans l'apprentissage automatique, il est utilisé pour déterminer si les modèles formés sur l'ensemble d'apprentissage (IST) sont également valables dans l'ensemble de validation.
Dans la SQ X, il peut être utilisé pour relancer l'évolution génétique lorsque la condition physique stagne dans cette partie.
- Hors échantillon - c'est la même chose que précédemment, cela représente une partie "inconnue" des données qui ne faisait pas partie de l'évolution
- Pas de commerce - partie spéciale qui signifie que la stratégie n'effectuera pas de transactions dans cette partie. Cela peut être utilisé par exemple pour sauter une partie au milieu des données qui ont une faible volatilité.
La recommandation générale en matière d'apprentissage automatique est de diviser les données historiques en trois parties distinctes : IST, ISV et OOS.

Une autre répartition possible pourrait être 60/20/20, ou placer la période hors échantillon au premier plan.
Sections de données multiples
Une autre nouveauté de SQ X B 125 est qu'il est possible de définir multiples Validation dans l'échantillon ou hors de l'échantillon pièceset non un seul, et dans l'ordre que vous souhaitez.
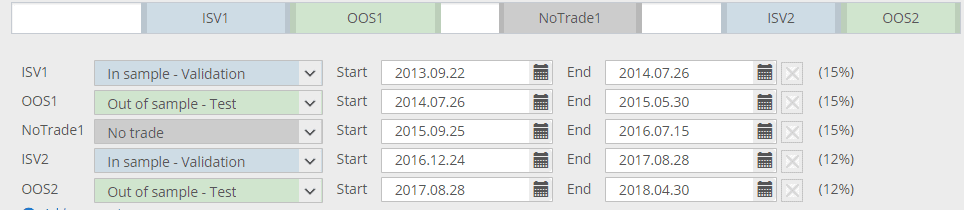
Dans l'image ci-dessus, les parties blanches sont toutes des échantillons de formation - ce sont les données sur lesquelles les stratégies sont élaborées.
Les parties bleues (ISV) sont des données sur lesquelles les stratégies sont vérifiées, et l'évolution peut être relancée lorsqu'elle stagne.
La partie grise (non commercialisée) est celle qui est omise - la stratégie n'est pas commercialisée ici.
Les parties vertes sont des parties OOS - elles ne font pas partie de l'évolution génétique et les stratégies sont évaluées sur des données inconnues.
Conditions et filtrage par section
Tous les indicateurs sont maintenant calculée également de manière indépendante pour chacune de ces partieset vous pouvez les utiliser dans vos conditions.
Par exemple, vous pouvez filtrer les stratégies dont le bénéfice net (OOS1) est inférieur à 80% du bénéfice net (OOS2) : Le bénéfice net (OOS1) est inférieur à 80% du bénéfice net (OOS2).
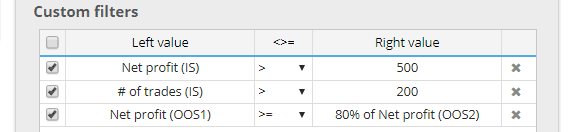
Cela vous permet d'utiliser un filtrage "plus strict" lorsque la stratégie doit être performante sur plusieurs parties de données.
 Tomas Vanek
Tomas Vanek

Merci de votre attention.
Ici, pour le bénéfice net (IS), IS comprend IST et ISV1 et ISV2. Ai-je raison ?
Good question. Anybody from the SQ team who want to answer?
Oui, c'est exact
Je me sens très bête en essayant de comprendre ce que cela signifie.
Si vous avez des questions spécifiques, n'hésitez pas à les poser.
Can you explain with more details what’s the difference between ISV and OOS? Maybe is something related to machine learning but I don’t get it
That is a data part in SQ X that is used to determine if strategy performance in IST (training part) holds also in ISV part. In SQ X it can be used to restart genetic evolution when fitness stagnates in this part. So it is kind of semi-OOS used to verify performance before it is verified on OOS