The new SQ build 125 introduces multiple data range parts. Until now, you were able to divide your history data to two parts only:
- In Sample – this is where the strategies are evolved using genetic evolution. This means that strategy is evaluated on this part of data, and its performance score (fitness) is computed from metrics in this part of data.This fitness then determines which strategies in population are selected to be crossed and mutated to create a new generation. The best strategies have highest probability to be chosen for this and thanks to this the population as a whole should get better with every generation.
- Out Of Sample – this is “unknown” part of data that was not part of evolution. It is used to verify that strategies work also on “unknown” data.
Genetic evolution doesn’t see this part of data.
The new build 125 adds two more possible types, making it 4 in total:
- In Sample Training (IST) – this is the same as In Sample that we had until now. Genetic evolution uses this part to determine fitness and rank the strategies in population.
- In Sample Validation (ISV) – a new part in SQ X that is used to determine if strategy performance in IST part holds also in ISV part.
In machine learning it is used to determine if models trained on Training set (IST) holds also in Validation set.
In SQ X it can be used to restart genetic evolution when fitness stagnates in this part.
- Out of sample – this is as same as before, it represents an “unknown” part of data that was not part of the evolution
- No Trade – special part that means that strategy will not trade in this part. It can be used for example to skip a part in the middle of data that has low volatility.
The general recommendation in machine learning is to split the history data to 3 same parts: IST, ISV and OOS.

Another possible split could be 60/20/20, or move Out of Sample period to the front.
Multiple data sections
Another new feature if SQ X B 125 is that you can define multiple In Sample Validation or Out of Sample parts, not just one, and in any order you want.
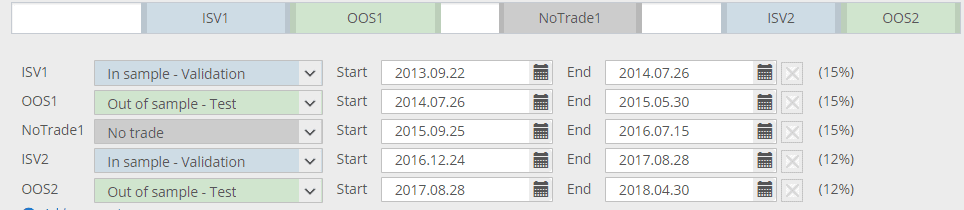
In the picture above the white parts are all In Sample training – these are the data on which strategies are evolved.
Blue (ISV) parts are data on which strategies are verified, and evolution can be restarted when it is stagnating.
Gray (no trade) part is the one that is left out – strategy doesn’t trade here.
Green parts are OOS parts – they are not part of genetic evolution and strategies are evaluated on unknown data.
Conditions and filtering by each section
All metrics are now computed also independently for each of these parts, and you can use them in your conditions.
For example, you can filter out strategies where: Net profit (OOS1) is worse than 80% of Net profit (OOS2).
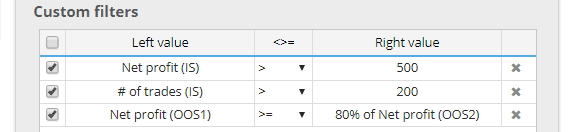
This allows you to use “stricter” filtering where strategy has to perform well on multiple parts of data.

 Tomas Vanek
Tomas Vanek

Thank you
Here, for Net profit (IS) , IS includes IST and ISV1 and ISV2. Am I right?
Good question. Anybody from the SQ team who want to answer?
Yes, correct
i feel very dumb trying to understand what this means.
if you have a specific questions feel free to ask
Can you explain with more details what’s the difference between ISV and OOS? Maybe is something related to machine learning but I don’t get it
That is a data part in SQ X that is used to determine if strategy performance in IST (training part) holds also in ISV part. In SQ X it can be used to restart genetic evolution when fitness stagnates in this part. So it is kind of semi-OOS used to verify performance before it is verified on OOS
Quick question… if we apply Ranking filters to “Full” will these factors be applied to the ISV part as well? Or must they be set to IST? And there’s also an option for “IS”, what’s the difference between “IS” and “IST” in SQX 139?
Thanks
Kim
Yes, full means all data is+oos parts included
Let me confirm so if I separated my data into four segments as follows….
OOS1, OOS2, ISV, IST
And in the rank filter I only put Profi Factor (Full) > 1.3
That is the equivalent of saying
Profit Factor (OOS1) > 1.3
Profit Factor (OOS2) > 1.3
Profit Factor (ISV) > 1.3
Profit Factor (IST) > 1.3
Because this is very different from
The whole data Profit Factor (OOS1) > 1.3
Hello, many thanks for this helpful article.
Which setting should I use to maximize the machine learning in the best way?
Many thanks,
Martin