O novo SQ build 125 introduz múltiplas peças da gama de dados. Até agora, você era capaz de dividir seus dados históricos em apenas duas partes:
- Em Amostra - é aqui que as estratégias são desenvolvidas utilizando a evolução genética. Isto significa que a estratégia é avaliada nesta parte dos dados, e sua pontuação de desempenho (adequação) é computada a partir da métrica nesta parte dos dados. Esta adequação determina então quais estratégias na população são selecionadas para serem cruzadas e mutantes para criar uma nova geração. As melhores estratégias têm maior probabilidade de serem escolhidas para isto e graças a isto a população como um todo deve melhorar a cada geração.
- Fora da amostra - esta é uma parte "desconhecida" dos dados que não fazia parte da evolução. É usado para verificar se as estratégias funcionam também sobre dados "desconhecidos".
A evolução genética não vê esta parte dos dados.
O novo build 125 acrescenta mais dois tipos possíveis, tornando-o 4 no total:
- Em Exemplo de Treinamento (IST) - isto é o mesmo que no In Sample que tivemos até agora. A evolução genética usa esta parte para determinar a aptidão e classificar as estratégias na população.
- Na validação de amostras (ISV) – uma nova parte no SQ X que é usada para determinar se o desempenho da estratégia na parte IST também é válido na parte ISV.
No aprendizado de máquinas, é usado para determinar se os modelos treinados em Conjunto de Treinamento (IST) também são válidos em Conjunto de Validação.
No SQ X ele pode ser usado para reiniciar a evolução genética quando a aptidão física estagna nesta parte.
- Fora de amostra – isto é o mesmo que antes, representa uma parte "desconhecida" dos dados que não fazia parte da evolução
- Sem comércio – parte especial que significa que a estratégia não será comercializada nesta parte. Ela pode ser usada, por exemplo, para pular uma parte no meio dos dados que tem baixa volatilidade.
A recomendação geral na aprendizagem de máquinas é dividir os dados do histórico em 3 partes iguais: IST, ISV e OOS.

Outra divisão possível poderia ser 60/20/20, ou sair do período da amostra para a frente.
Múltiplas seções de dados
Outra novidade se o SQ X B 125 é que você pode definir múltiplo Na validação da amostra ou fora da amostra peçase não apenas uma, e em qualquer ordem que você queira.
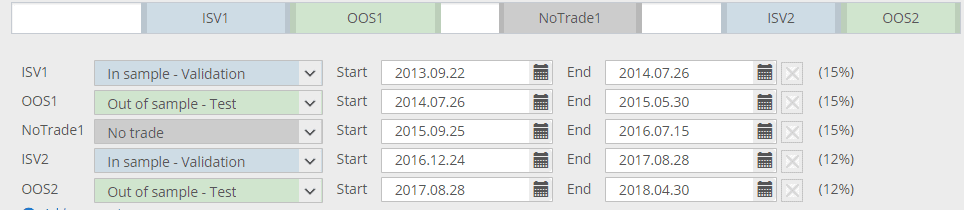
Na figura acima, as partes brancas estão todas em treinamento por amostragem - estes são os dados sobre os quais as estratégias são desenvolvidas.
As partes azuis (ISV) são dados sobre os quais as estratégias são verificadas, e a evolução pode ser reiniciada quando está estagnada.
A parte cinza (sem comércio) é a que fica de fora - a estratégia não negocia aqui.
As partes verdes são partes OOS - não fazem parte da evolução genética e as estratégias são avaliadas com base em dados desconhecidos.
Condições e filtragem por cada seção
Todas as métricas são agora computadas também independentemente para cada uma dessas partese você pode utilizá-los em suas condições.
Por exemplo, você pode filtrar estratégias onde: O lucro líquido (OOS1) é pior que 80% de lucro líquido (OOS2).
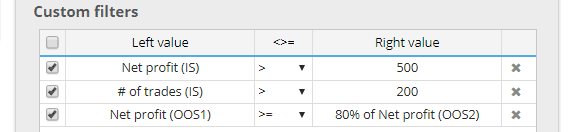
Isto permite que você use uma filtragem "mais rigorosa" onde a estratégia tem que funcionar bem em várias partes dos dados.
 Tomas Vanek
Tomas Vanek

Obrigado
Aqui, para o lucro líquido (IS), IS inclui IST e ISV1 e ISV2. Estou certo?
Good question. Anybody from the SQ team who want to answer?
Sim, correto
Estou me sentindo muito burro ao tentar entender o que isso significa.
Se você tiver alguma pergunta específica, fique à vontade para perguntar
Can you explain with more details what’s the difference between ISV and OOS? Maybe is something related to machine learning but I don’t get it
That is a data part in SQ X that is used to determine if strategy performance in IST (training part) holds also in ISV part. In SQ X it can be used to restart genetic evolution when fitness stagnates in this part. So it is kind of semi-OOS used to verify performance before it is verified on OOS