La nuova build 125 di SQ introduce più parti dell'intervallo di dati. Finora era possibile dividere i dati dello storico solo in due parti:
- In Campione - È qui che le strategie vengono evolute utilizzando l'evoluzione genetica. Ciò significa che la strategia viene valutata su questa parte di dati e il suo punteggio di performance (fitness) viene calcolato in base alle metriche di questa parte di dati. Questo fitness determina quindi quali strategie nella popolazione vengono selezionate per essere incrociate e mutate per creare una nuova generazione. Le strategie migliori hanno la massima probabilità di essere scelte per questo scopo e grazie a ciò la popolazione nel suo complesso dovrebbe migliorare a ogni generazione.
- Fuori campione - si tratta di una parte "sconosciuta" dei dati che non faceva parte dell'evoluzione. Viene utilizzata per verificare che le strategie funzionino anche su dati "sconosciuti".
L'evoluzione genetica non vede questa parte di dati.
La nuova build 125 aggiunge altri due tipi possibili, che diventano 4 in totale:
- Formazione campione (IST) - è la stessa di In Sample che abbiamo avuto finora. L'evoluzione genetica utilizza questa parte per determinare la fitness e classificare le strategie nella popolazione.
- Convalida del campione (ISV) - una nuova parte in SQ X che viene utilizzata per determinare se le prestazioni della strategia nella parte IST sono valide anche nella parte ISV.
Nell'apprendimento automatico viene utilizzato per determinare se i modelli addestrati sull'insieme di addestramento (IST) sono validi anche nell'insieme di validazione.
In SQ X può essere utilizzato per riavviare l'evoluzione genetica quando la fitness ristagna in questa parte.
- Fuori campione - è lo stesso di prima, rappresenta una parte "sconosciuta" di dati che non faceva parte dell'evoluzione
- Nessun commercio - parte speciale che significa che la strategia non opererà in questa parte. Può essere utilizzata, ad esempio, per saltare una parte nel mezzo dei dati che hanno una bassa volatilità.
La raccomandazione generale nell'apprendimento automatico è quella di dividere i dati storici in tre parti uguali: IST, ISV e OOS.

Un'altra possibile suddivisione potrebbe essere 60/20/20, oppure spostare il periodo fuori campione nella parte anteriore.
Più sezioni di dati
Un'altra novità di SQ X B 125 è che è possibile definire multiplo Convalida nel campione o fuori campione parti, non solo uno, e in qualsiasi ordine si voglia.
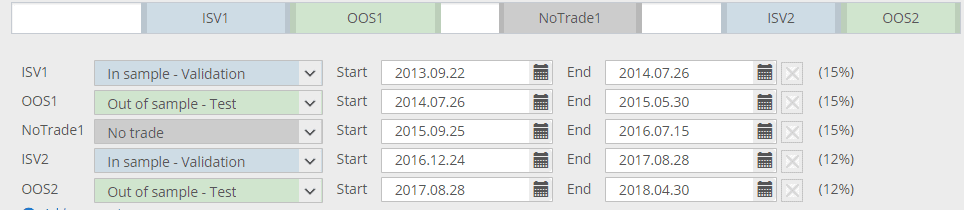
Nell'immagine qui sopra, le parti bianche sono tutte le formazioni In Sample: sono i dati su cui si evolvono le strategie.
Le parti blu (ISV) sono dati su cui vengono verificate le strategie e l'evoluzione può essere riavviata quando ristagna.
La parte grigia (no trade) è quella che viene lasciata fuori: la strategia non viene scambiata qui.
Le parti verdi sono parti OOS - non fanno parte dell'evoluzione genetica e le strategie sono valutate su dati sconosciuti.
Condizioni e filtri per ogni sezione
Tutte le metriche sono ora calcolati anche in modo indipendente per ciascuna di queste partie potete utilizzarli nelle vostre condizioni.
Ad esempio, è possibile filtrare le strategie in cui: Il profitto netto (OOS1) è peggiore di 80% del profitto netto (OOS2).
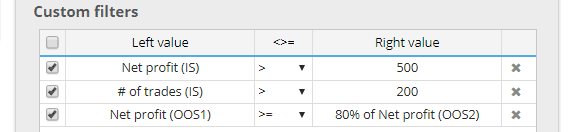
Ciò consente di utilizzare un filtraggio "più rigoroso", quando la strategia deve funzionare bene su più parti dei dati.
 Tomas Vanek
Tomas Vanek

Grazie
In questo caso, per l'Utile netto (IS), IS include IST e ISV1 e ISV2. Ho ragione?
Good question. Anybody from the SQ team who want to answer?
Sì, corretto
Mi sento molto stupido a cercare di capire cosa significhi.
se avete domande specifiche non esitate a chiedere
Can you explain with more details what’s the difference between ISV and OOS? Maybe is something related to machine learning but I don’t get it
That is a data part in SQ X that is used to determine if strategy performance in IST (training part) holds also in ISV part. In SQ X it can be used to restart genetic evolution when fitness stagnates in this part. So it is kind of semi-OOS used to verify performance before it is verified on OOS