El nuevo SQ build 125 introduce múltiples partes de rango de datos. Hasta ahora, sólo se podían dividir los datos históricos en dos partes:
- En la muestra - Aquí es donde las estrategias evolucionan mediante evolución genética. Esto significa que la estrategia se evalúa en esta parte de los datos, y su puntuación de rendimiento (aptitud) se calcula a partir de métricas en esta parte de los datos. Esta aptitud determina entonces qué estrategias de la población se seleccionan para ser cruzadas y mutadas para crear una nueva generación. Las mejores estrategias tienen más probabilidades de ser elegidas y, gracias a ello, la población en su conjunto debería mejorar con cada generación.
- Fuera de muestra - se trata de una parte "desconocida" de los datos que no formaba parte de la evolución. Se utiliza para verificar que las estrategias funcionan también con datos "desconocidos".
La evolución genética no ve esta parte de los datos.
La nueva construcción 125 añade dos tipos posibles más, lo que hace un total de 4:
- Formación en muestras (IST) - esto es lo mismo que In Sample que teníamos hasta ahora. La evolución genética utiliza esta parte para determinar la aptitud y clasificar las estrategias en la población.
- Validación de muestras (ISV) - una nueva parte en SQ X que se utiliza para determinar si el rendimiento de la estrategia en la parte IST se mantiene también en la parte ISV.
En el aprendizaje automático, se utiliza para determinar si los modelos entrenados en el conjunto de entrenamiento (IST) son válidos también en el conjunto de validación.
En SQ X puede utilizarse para reiniciar la evolución genética cuando la aptitud se estanca en esta parte.
- Fuera de la muestra - esto es igual que antes, representa una parte "desconocida" de datos que no formaba parte de la evolución
- No Comercio - parte especial que significa que la estrategia no operará en esta parte. Se puede utilizar, por ejemplo, para omitir una parte en medio de los datos que tiene baja volatilidad.
La recomendación general en el aprendizaje automático es dividir los datos históricos en 3 partes iguales: IST, ISV y OOS.

Otra posible división podría ser 60/20/20, o mover el periodo Fuera de Muestra al frente.
Múltiples secciones de datos
Otra novedad de SQ X B 125 es que puede definir varios Validación en la muestra o fuera de la muestra piezasno sólo uno, y en el orden que quieras.
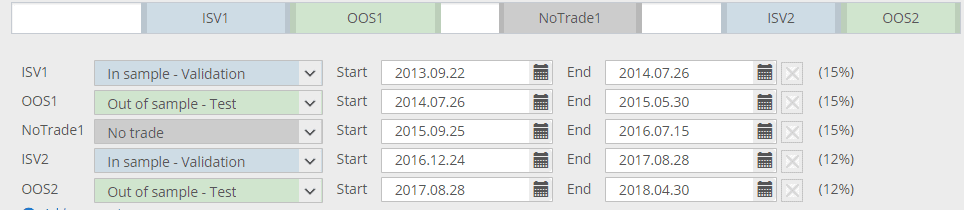
En la imagen de arriba, las partes blancas son todos los entrenamientos de la muestra: son los datos sobre los que evolucionan las estrategias.
Las partes azules (ISV) son datos sobre los que se verifican las estrategias, y la evolución puede reiniciarse cuando está estancada.
La parte gris (no trade) es la que queda fuera - la estrategia no se negocia aquí.
Las partes verdes son partes OOS - no forman parte de la evolución genética y las estrategias se evalúan sobre datos desconocidos.
Condiciones y filtrado por cada sección
Todas las métricas son ahora calculado también independientemente para cada una de estas partesy puedes utilizarlos en tus condiciones.
Por ejemplo, puede filtrar las estrategias en las que: Beneficio neto (OOS1) es peor que 80% de Beneficio neto (OOS2).
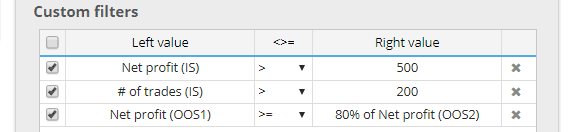
Esto le permite utilizar un filtrado "más estricto" cuando la estrategia tiene que funcionar bien en varias partes de los datos.
 Tomas Vanek
Tomas Vanek

Gracias
Aquí, para el beneficio neto (IS) , IS incluye IST e ISV1 e ISV2. ¿Estoy en lo cierto?
Good question. Anybody from the SQ team who want to answer?
Sí, correcto.
me siento muy tonto tratando de entender lo que esto significa.
si tiene alguna pregunta concreta, no dude en formularla
Can you explain with more details what’s the difference between ISV and OOS? Maybe is something related to machine learning but I don’t get it
That is a data part in SQ X that is used to determine if strategy performance in IST (training part) holds also in ISV part. In SQ X it can be used to restart genetic evolution when fitness stagnates in this part. So it is kind of semi-OOS used to verify performance before it is verified on OOS