IS and OOS Degradation Score
Page contents
What it does
Every robust backtest reserves a chunk of data the strategy was never optimized on — the Out-of-Sample period. The honest answer to “did this strategy actually learn the market, or just memorize the training data?” lives in the gap between IS and OOS performance. This plugin computes that gap automatically, for every key metric, and condenses it into something you can read in under ten seconds.
Open the IS ↔ OOS Degradation Scorecard tab in Results, select any strategy with an IS/OOS split, and the plugin does the rest.
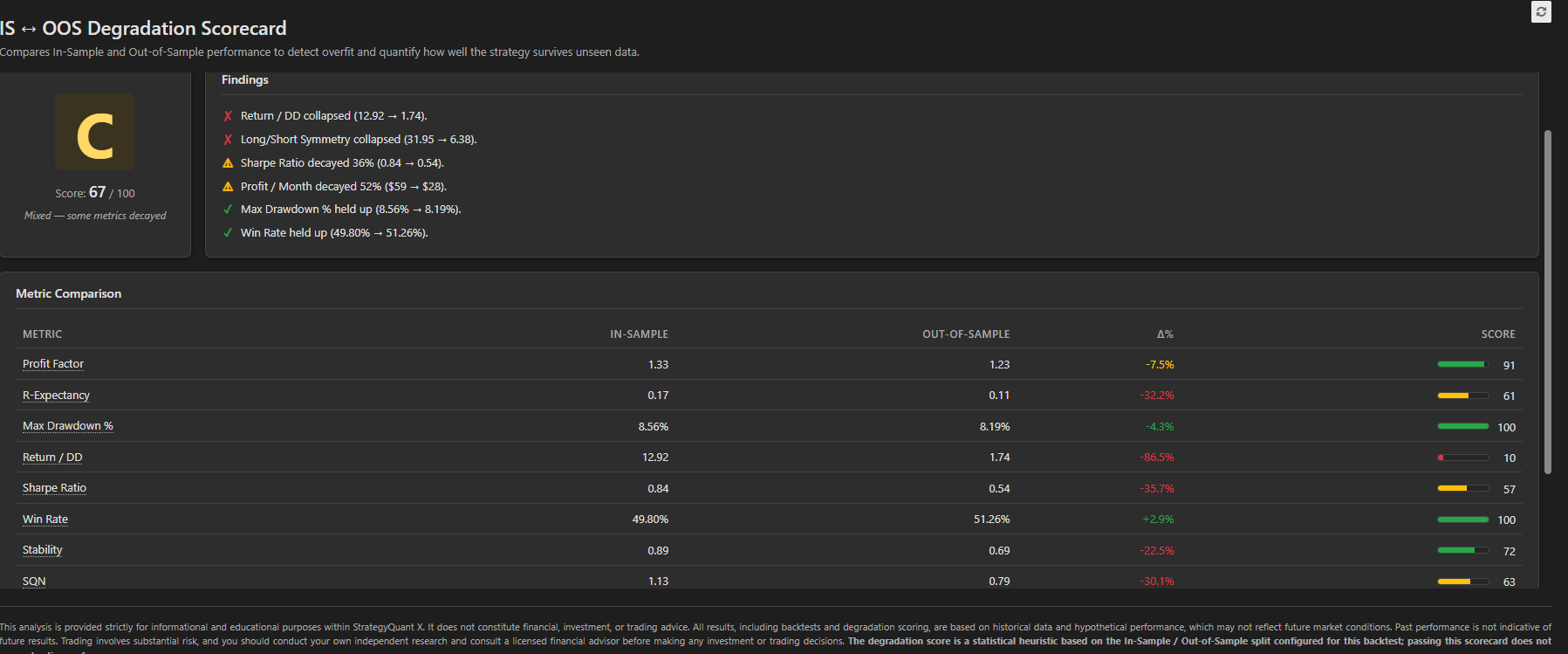
What you get
- A single composite grade (A–F) with a 0–100 score, color-coded so a glance tells the story.
- A findings panel that turns the numbers into plain English: “Profit Factor fell below 1.0 — strategy is unprofitable Out-of-Sample”, “Max drawdown more than doubled”, “Win rate held up (52% → 51%)”. The top six most important observations, prioritised from critical to good.
- A side-by-side metric table across 10 robustness indicators: Profit Factor, R-Expectancy, Max Drawdown %, Return/DD, Sharpe, Win Rate, Stability, SQN, monthly profit, and long/short symmetry. Each row shows the IS value, the OOS value, the % change, and an individual 0–100 score bar.
- An adequacy banner that warns when you only have 22 OOS trades and the result, however good, is statistically meaningless.
- Hover tooltips on every metric explaining what it is, what its IS→OOS change implies, and what counts as alarming.
How the scoring works
Each metric is scored on a retention curve — how well does OOS performance hold up versus IS? Full retention (or improvement) scores 100; mild decay scores 75; significant decay 40; collapse 0. Critical sign-flips (Profit Factor crossing below 1.0, expectancy turning negative, Sharpe going negative) force the metric’s score straight to zero, because in those cases the strategy fundamentally broke. Metrics are then combined with risk-weighted weights that give equal importance to profitability, risk, and consistency.
Who it’s for
- Strategy developers doing final sanity-check before adding a candidate to a portfolio.
- Prop firm traders who need to be confident a passed evaluation strategy wasn’t curve-fit.
- Quants reviewing batches of strategies generated by AlgoWizard or Builder — sort by grade, focus on the As and Bs, throw the Fs back.
What it is not
This is a statistical heuristic, not a guarantee. A good grade means the strategy survived a single holdout split — it does not predict live performance. Use it as one filter among several (Monte Carlo, walk-forward, robustness tests), not as the only one.

This is interesting ! Thank you Tomas !